
1. ATTR 간단 예제
1.1 단일 값만 존재하는 행 찾기
→ 한 번만 팔린 제품 구하기
- 한 번도 팔리지 않는 제품은 보통 제거를 함
- 그러나 한 번만 팔린 제품은 따로 리스트를 만들어 관리를 해주기도 함
- 한 번만 팔린 제품은 한 번도 팔리지 않는 것과 완전히 다름! (⭐ 이커머스에선 중요)
📌 단일 값만 존재하는 행을 리스트 만들기
① Order ID 필드를 특성으로 드래그앤드랍
② 필터에 Order ID 드래그앤 드랍
③ 필터에서 다중값 제거

1.2 문자열에 대한 집계를 수행
→ 같은 차원 다른 집계 (자주 사용하지는 않음)
📌 Region에서 Central은 합계를, 나머지 지역은 평균값을 나타내기
① 계산된 필드 만들기
// 잘못된 식
IF [Region] = 'Central' THEN SUM([Sales])
ELSE AVG([Sales])
END▼
// 수정한 식 → ATTR 추가
IF ATTR([Region]) = 'Central' THEN SUM([Sales])
ELSE AVG([Sales])
END
② 측정값으로 추가하기

1.3 단일 값/다중 값 추가 확인
→ 도구설명에 특성으로 설정된 Country/Region 필드를 드래그앤드랍
세부수준이 깊거나 얕은 카테고리임을 확인할 수 있음

2. 결합된 필드 - 차원 정렬 nested setting
기본 정렬을 할 때, 각 Category 별로 정렬이 되는 것이 아니라 전체의 기준으로 모든 Category의 데이터가 정렬이 된다.
즉, 각 Category 별로 특정 값에 대해 정렬이 되지 않기에 각 카테고리 내의 오름/내림차순에 대한 순위를 확인하기 어렵다.
▼ 아래의 그래프는 State/Province에 대한 정렬이 전체 카테고리에 적용이 되었다.

💡 그래서 이러한 경우에는 ‘결합된 필드’를 만들어 정렬하면 된다.
① Category 필드와 State/Province 필드를 Ctrl 키 + 클릭
② 우클릭 > 만들기 > 결합된 필드
③ 결합된 필드를 세부정보에 드래그앤드랍
④ 결합된 필드 우클릭 > 정렬

⭐ 마크 내에 세부정보(결합된 필드)가 색상보다 위에 있어야 함!
그렇지 않으면 State/Province 기준으로 정렬이 됨
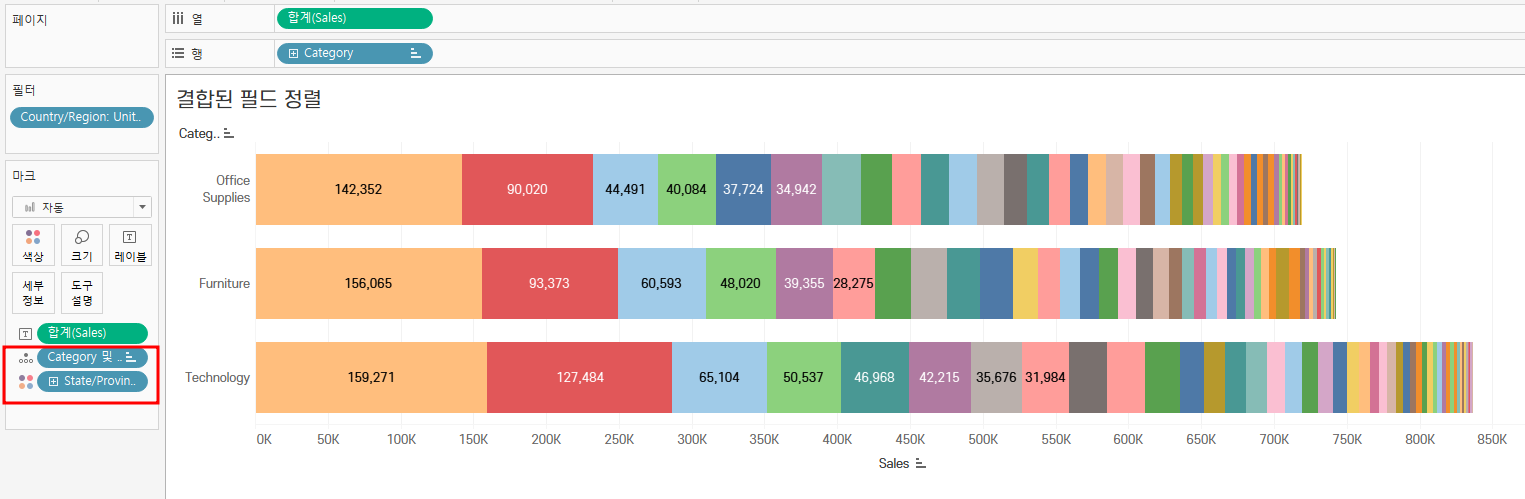
결합된 필드 기준으로 텍스트가 생성됨 → 한번 해보기
3. 집합
3.1 집합이란?
- 둘이 분리하는 것 (IN or OUT을 정해주는 것)
- 필터도 비슷한 기능이 있으나 어떤 점이 다른가?
- 필터 : 내가 관심이 있는 것만 화면에 담기고 나머지는 제외
- 집합 : 관심 있고 없고 상관하지 않고 제외하지 않음 (기준만 정하고 다 보여줌)
→ 집합이 필터보다 상위의 개념 (집합이 필터를 포함하고 있기 때문에)
→ 그렇기에 집합을 필터로 넣으면 필터에서도 사용이 가능함
- T/F 필터와 다른 점?
- 낮은 차원에서는 보기가 똑같으나 카테고리 등 차원이 깊어졌을 때는 차이가 있음
- T/F 필터 : thres가 넘는 카테고리만 색이 바뀜. 항목을 구분해서 봐야 함
- 집합 : 모두 집계가 해당되면 그 기준으로 색이 다 바뀜
📌 profit 합계 기준 상위 n명의 Customers 나타내기
① 매개변수 만들기 (Top Customers / 해당 데이터에는 생성되어 있음)
② 집합 만들기 (Top Customers by Profit / 해당 데이터에는 생성되어 있음)

③ 집합을 행에 드래그앤드랍
▶ 집합의 기준에 맞춰서 해당하는 데이터는 IN, 그렇지 않은 데이터는 OUT으로 표현됨

3.2 집합 만들기
① 매출액 기준 값 매개변수 만들기 (sales_thres)
② 집합 만들기 (sales customer - 집합)
→ 조건 > 수식 기준
// 매출액 총 액이 기준 값 이상인 데이터
SUM([Sales]) >= [sales thres]③ 위의 집합을 색상에 드래그앤드랍
▶ 매출액 기준 값 (sales_thres) 이상인 데이터만 빨간색으로 표현이 됨

3.3 집합과 T/F 필드(필터)
1) 집합과 T/F 필드 비교 (낮은 차원)
▶ 집합과 T/F 필드와 동일하게 결과값이 나온다.
① T/F 필드 만들기 (집합 똑같은 계산식)
// 집합 조건에 넣었던 식과 동일함
SUM([Sales]) >= [sales thres]
② T/F 필드를 색상에 드래그앤드랍

2) 집합과 T/F 필드 비교 (높은 차원)
▶ 집합과
단순 총 합계가 아닌 카테고리도 함께 표현하여 확인해보자.
✅ 집합 사용
카테고리를 추가하여도 총합계만 기준값을 넘으면 IN으로 색상이 표현됨
집합의 경우, Customer Name에서 만들었기 때문에 그 총합계 기준으로 표현이 됨. 카테고리를 추가해도 변경되지 않음.

✅ T/F 필드 사용
T/F 필드의 기준은 VLOD의 값, 즉 현재 보여지는 값들임
그렇기 때문에 각 카테고리 별 매출액에서도 기준 값이 넘는 값들에만 IN으로 색상이 표현됨

3.4 집합과 FIXED LOD
⭐ 집합 = FIXED LOD + 필터
그러면 fixed LOD를 집합 대신 쓰면 되지 않을까?
→ 퍼포먼스 테스트에서 fixed LOD가 느리기 때문에 집합을 쓰는 것이 낫다.
① fixed LOD 함수를 사용하여 필드 만들기 (fixed_sales thred)
// 식은 집합에서 사용한 식과 동일
{ FIXED [Customer Name] : SUM([Sales])>=[sales thres]}
② 필드를 색상에 드래그앤드랍

3.5 추가 예시
📌 매출액 합계가 10,000이 넘는 customer들의 매출 합계
→ 비율을 확인할 때 주로 사용함
1) T/F 필드 사용
Category 별 합계를 기준값과 비교

2) 집합 사용
매출액 합계가 10,000인 customer를 IN으로 색상 표현
+) IN에 해당하는 customer의 매출액의 합계를 수치로 표현

4. LOD
VLOD를 바꿀 수 있는 것은 ‘차원’이다.
→ 마크가 바뀌는 모든 기능으로 VLOD를 바꿀 수 있다. (열, 행 등등)
✔ INCLUDE
- 차원을 VLOD에서 보이지 않는 뒷단에 추가하고 싶다면 사용
- 규모 확인 가능
✔ EXCLUDE
- 차원을 VLOD에서 보이지 않는 뒷단에서 제거하고 싶다면 사용
- 비중 확인 가능
✔ FIXED
- FIXED로 고정시킨 차원이 VLOD에 보여져 있을 때
- FIXED로 고정시킨 차원이 VLOD에 보여지 있지 않을 때
- 차원 고정 + 기준
4.1 INCLUDE
일단, 데이터셋의 뎁스가 상대적으로 깊어야 함.
집계를 2번 해야 할 때 (평균의 최대값, 최소값의 평균 등)
INCLUDE를 적용한 뎁스보다 위인 뎁스에서 데이터의 비교가 가능함
1) 이론 이해하기
① include를 사용한 필드 만들기 (include_sub_avg_sales)
→ Sub-Category를 기준으로 매출액의 평균 계산
{ INCLUDE [Sub-Category]:AVG([Sales])}
② 이중축으로 include 반영x / 반영o 그래프 비교하기
✔ Sub-Category 기준
→ include를 반영한 그래프와 반영하지 않은 그래프가 동일함

✔ Category 기준
- include를 적용하지 않은 그래프 : Category 내에 있는 모든 데이터의 평균
- include를 적용한 그래프 : Sub-Category 평균 데이터의 평균
(ex. Furniture : (497+530+95+638)/4)

2) INCLUDE 사용 예시
평균으로 봤을 때는 알 수 없지만, 실제로는 데이터끼리 값이 차이가 많이 나는 경우가 있는데,
이를 INCLUDE를 활용해서 확인할 수 있다.
✔ include 적용 전 그래프
▶ New York의 평균 매출액은 높은 편이 아님을 확인할 수 있다.

✔ include 적용 후 그래프 (각 시/도 내 최댓값, 최솟값 도시를 나타냄)
① 이에 적용할 include 필드 만들기
// include_city_avg_sales
{include [City]: AVG([Sales])}
② include 필드의 최솟값, 최댓값 그래프를 이중축으로 표현하기
③ 최솟값과 최댓값이 차이가 많이 나는 순으로 정렬하기
→ 최솟값, 최댓값의 차이를 계산하는 필드 만들기
// diff
max([include_city_avg_sales])-MIN([include_city_avg_sales])
→ State/Province 우클릭 > 정렬

▶ New York의 매출액 최대, 최솟값의 차이가 가장 많이 난다.
해당 데이터를 통해 New York의 빈부격차가 큰 것을 확인할 수 있다.

4.2 EXCLUDE
① exclude를 사용한 필드 만들기 (exclude_sub_avg_sales)
→ Sub-Category를 기준으로 매출액의 평균 계산한 것을 제외
{ EXCLUDE [Sub-Category]:AVG([Sales])}
② 이중축으로 exclude 반영x / 반영o 그래프 비교하기
✔ Category 기준
→ exclude를 반영한 그래프와 반영하지 않은 그래프가 동일함

✔ Sub-Category 기준
- exclude를 적용하지 않은 그래프 : Category 내에 있는 모든 데이터의 평균
- exclude를 적용한 그래프 : Category 전체 데이터의 평균

2) EXCLUDE 사용 예시
exclude는 특정 값을 기준으로 차이나 비중을 확인하기 위해 사용한다.
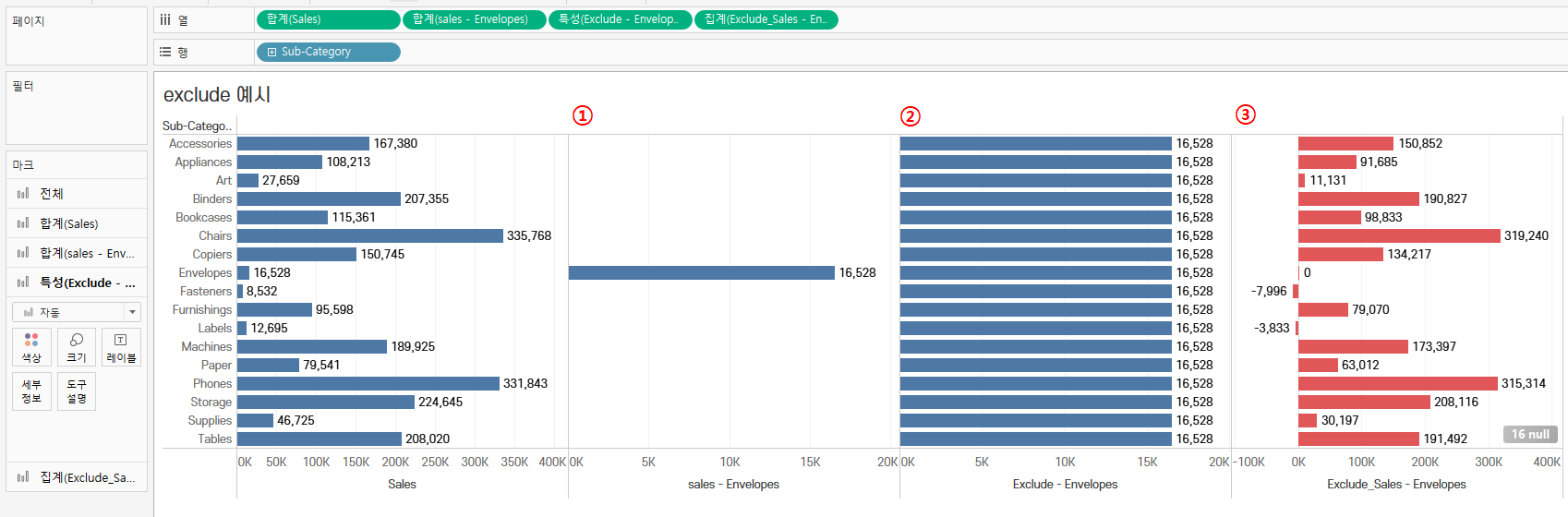
📌 Sub-Category의 Envelopes의 매출 합계와 Sub-Category의 매출 합계의 차이 구하기
① Sub-Category의 Envelopes의 매출 합계 구하기
→ Envelopes의 데이터만 출력하기 위해 필드 만들기
// sales - Envelopes
IF [Sub-Category] = 'Envelopes' THEN [Sales]
ELSE NULL
END
② Exclude를 활용하여 모든 Sub-Category에서 Envelopes의 매출 합계를 나타내기
→ Sub-Category에 있는 데이터를 SUM([sales - Envelopes])로 표현하라
// Exclude - Envelopes
{ EXCLUDE [Sub-Category]:SUM([sales - Envelopes])}
③ 각 Sub-Category의 매출 합계에서 Envelopes의 매출 합계 빼기
// Exclude_Sales - Envelopes
SUM([Sales]) - ATTR([Exclude - Envelopes])
💡 회고
✔ 유익한 점 & 배운점
ATTR, 결합된 필드, 집합, LOD에 대해 배웠다.
어려워서 이해가 잘 되지 않은 개념이라 쉽지 않았지만 직접 해봄으로써 기능을 익히며 이해하려고 노력하고 있다.
특히, 오늘은 이 기능을 익히는 개인 공부 시간을 넉넉히 주셔서 다행히 여러 시도를 해보면서 공부할 수 있었다.
✔ 스스로 아쉬운 점 & 개선할 점
LOD에 대해 이해하는 것이 어려웠다.
예시를 보면서 더욱 헷갈리고 이게 왜 이런식으로 표현되지?라는 생각에 머리가 더더욱 복잡해졌다.
다른 데이터를 활용해서 기능을 적용해볼 예정이다! :)
'웅진X유데미 STARTERS > TIL (Today I Learned)' 카테고리의 다른 글
| [스타터스 TIL] 34일차.태블로 실전 트레이닝 (10) - 팀 프로젝트 진행 (0) | 2023.03.26 |
|---|---|
| [스타터스 TIL] 33일차.태블로 실전 트레이닝 (9) - LOD (INCLUDE, EXCLUDE, FIXED) (0) | 2023.03.26 |
| [스타터스 TIL] 31일차.태블로 실전 트레이닝 (7) - 날짜 필터링, ATTR (0) | 2023.03.22 |
| [스타터스 TIL] 30일차.태블로 실전 트레이닝 (6) - PRIMARY 함수, RANK 함수 (0) | 2023.03.20 |
| [스타터스 TIL] 29일차.태블로 실전 트레이닝 (5) - MapBox, 태블로 추가 기능 (0) | 2023.03.17 |