
1. 새롭게 알게된 내용
1.1 데이터프레임(DataFrame)
1) 랜덤 보기
- df.sample(n) : 랜덤 n개의 데이터 보기 (n을 생략하면 1개의 샘플 출력)
- df.sample(frac = ) : 랜덤 샘플 비율로 보기 (지정한 비율의 샘플을 출력)
2) 높은 순, 낮은 순 보기
- df.nlargest(갯수, 컬럼명) : 컬럼명에서 높은 순으로 n개의 데이터 출력
- df.nsmallest(갯수, 컬럼명) : 컬럼명에서 낮은 순으로 n개의 데이터 출력
3) 데이터 요약 보기
- df.shape : 행,열의 크기 보기
- df.columns : 컬럼명 보기
- df.index : 인덱스 보기
- df.dtypes : 데이터의 자료형 보기
- df.info() : 데이터프레임의 정보보기
- 컬럼.unique() : 컬럼의 유니크한 데이터 뽑기
- 컬럼.value_counts() : 컬럼의 유니크한 값의 갯수 보기
- df.describe() : 요약 통계보기
4) 시리즈 만들기
- 시리즈는 엑셀 시트의 열 1개를 의미한다. (1차원 리스트 형태)
- 시리즈에는 index와 value가 있다.
- pd.Series(리스트)
- 시리즈의 index 가져오기 : 시리즈.index
- 시리즈의 value 가져오기 : 시리즈.values
5) 시리즈 주요 메서드
- 값 정렬 : 시리즈.sort_values( )
- 인덱스 정렬 : 시리즈.sort_index( )
- 인덱스 리셋 : 시리즈.reset_index( ) --> 행번호로 인덱스 재지정
- 특정 값을 가진 시리즈 값을 교체 : replace(찾을값, 교체할값)
- 시리즈를 데이터프레임으로 변환 : 시리즈.to_frame( )
6) 데이터 추출 (특정 값)
- 컬럼.isin(값리스트)
# 이름이 Amy, Rose인 데이터 추출
df[df['name'].isin(['Amy', 'Rose'])]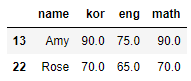
7) 데이터 추출 (인덱스)
✔ 행 데이터 추출
- df.loc[인덱스] : 시리즈 형태로 추출되며 하나의 인덱스만 사용 가능함
- df.loc[인덱스 리스트] : 데이터프레임 형태로 추출되며, 한 개 이상의 인덱스 사용 가능
✔ 행, 열 데이터 추출
- df.loc[인덱스, 컬럼명] : 특정 행과 열 데이터 값이 추출됨
- 특정 인덱스의 여러 컬럼 데이터 추출 → df.loc[인덱스, 컬럼명 리스트]
- 여러 인덱스의 특정 컬럼 데이터 추출 → df.loc[인덱스 리스트, 컬럼명]
- 여러 인덱스의 여러 컬럼 추출 → df.loc[인덱스 리스트, 컬럼명 리스트]
- 모든 행에서 특정 컬럼 가져오기 → df.loc[:, 컬럼명] / df.loc[:, 컬럼명 리스트]
8) 데이터 추출 (행, 열 번호)
✔ 행 데이터 추출
- df.iloc[행번호 / 행번호 리스트 / 행번호 슬라이스]
✔ 행, 열 데이터 추출
- df.iloc[행번호, 열번호]
- df.iloc[행번호, 열번호 리스트]
- df.iloc[행번호 리스트, 열번호]
- df.iloc[행번호 리스트, 열번호 리스트]
- df.iloc[행번호 슬라이싱, 열번호 슬라이싱]
✔ df.iloc 의 경우, 음수를 사용할 수 있음 (음수 행/열 번호)
9) 행/열 변경
- 열 추가/수정 → df[’컬럼’] = 추가/수정할 데이터
- 열 삭제 → df.drop(columns = 삭제할 컬럼 리스트, inplace = True)
- 컬럼명 한번에 변경 (갯수가 동일해야 함) → df.columns = 컬럼 리스트
- 특정 컬럼명 변경 → df.rename(columns = {현 컬럼명 : 변경 컬럼명, ...})
- 행 추가 및 인덱스 재지정 → df.append({추가 데이터}, ignore_index = True)
- 추가할 데이터는 딕셔너리 형태여야 함
- ignore_index = True : 인덱스 재지정
- 특정 인덱스의 행 추가/수정 → df.loc[인덱스] = 추가/수정할 데이터
- 행 삭제 → df.drop(index = 삭제할 인덱스 리스트, inplace = True)
- 전체 인덱스명 변경 → df.index = 인덱스명 리스트
- 특정 인덱스명 변경 → df.index.rename(index = {현 인덱스명 : 변경 인덱스명, ...})
✔ inplace = True : 변경할 사항을 현 데이터프레임에 저장
1.2 함수 적용
✔ 함수로 행/열 데이터 집계하기
- df.apply(함수명, axis = 0) : 열 단위 함수 적용
- df.apply(함수명, axis = 1) : 행 단위 함수 적용
# 합계 구하기
def get_sum(x):
return x.sum()
# 학생 별 점수 합계 (행 단위)
df_copy['sum'] = df.apply(get_sum, axis = 1)
# 과목 별 점수 합계 (열 단위)
df_copy.loc['sum'] = df.apply(get_sum, axis = 0)
1.3 결측치 처리
1.3.1 결측치 삭제
- df.dropna() : 결측치가 존재하는 모든 행 삭제
- df.dropna(axis = 1) : 결측치가 존재하는 모든 열 삭제
1.3.2 결측치 대치
- df.fillna(특정값) : 특정 값으로 채우기
- df.fillna(method = 'ffill') : 이전 값으로 채우기
- df.fillna(method = 'bfill') : 다음 값으로 채우기
- df.fillna({컬럼명:값, ...}) : 컬럼 별로 값을 지정하여 채우기
1.4 자료형 변환
- df.astype('자료형') / 시리즈.astype('자료형')
# 실수형으로 변환
df = df.astype('float64')
# 문자열로 변환
df = df.astype('str')
# 정수형으로 변환 → 오류 발생 (이 경우, 실수로 변환 후 정수로 변환해야 함)
df = df.astype('int')
# 실수 변환 후, 정수로 변환
df = df.astype('float').astype('int)
1.4.1 자료형이 혼합된 컬럼을 숫자형으로 변환
- pd.to_numeric(컬럼, errors = 'ignore') : 숫자로 변경할 수 없는 값이 있으면 작업 x
- pd.to_numeric(컬럼, errors = 'coerce') : 숫자로 변경할 수 없는 값은 NaN으로 설정
- pd.to_numeric(컬럼, errors = 'raise') : 숫자로 변경할 수 없는 값이 있으면 에러(default)
- `astype`의 경우, 숫자로 변경할 수 없는 데이터가 섞여있으면 에러가 발생함
- `pd.to_numeric`은 숫자로 변경할 수 없는 데이터를 어떻게 처리할지 여러 옵션을 설정할 수 있음
1.4.2 시계열 데이터로 변환
- 카테고리형으로 변환 → df[컬럼].astype('category')
- 카테고리 이름 변경 → df[컬럼].cat.categories = 카테고리 리스트
- 누락된 카테고리 추가 → df[컬럼].cat.set_categories(카테고리 리스트)
1.5 시계열 자료
1.5.1 컬럼을 datetime 자료형으로 변경하기
→ pd.to_datetime(컬럼)
# 출생, 사망 컬럼을 datetime 자료형으로 변경하기
df['출생'] = pd.to_datetime(df['출생'])
df['사망'] = pd.to_datetime(df['사망'])
df.dtypes
[out]
이름 object
주요경력 object
출생 datetime64[ns]
사망 datetime64[ns]
dtype: object
1.5.2 연, 월, 일, 분기 출력하기
- 컬럼.dt.year
- 컬럼.dt.month
- 컬럼.dt.day
- 컬럼.dt.quarter
1.5.3 요일, 월 이름 추출하기
- 컬럼.dt.strftime('%a') : 요약된 요일이름
- 컬럼.dt.strftime('%A') : 긴 요일이름
- 컬럼.dt.strftime('%w') : 숫자요일(0:일요일)
- 컬럼.dt.strgtime('%b') : 요약된 월이름
- 컬럼.dt.strftime('%B') : 긴 월이름
1.6 데이터프레임 연결하기
1.6.1 concat
- pd.concat(데이터프레임 리스트, axis = )
- 동일한 컬럼명/인덱스 기준으로 데이터프레임이 연결됨
# 컬럼명 기준으로 연결하기 → axis = 0 (default)
pd.concat([df1, df2, df3])
# 인덱스 기준으로 연결하기 → axis = 1
pd.concat([df1, df2, df3], axis = 1)
# 공통된 컬럼만 남기고 연결하기 → join = 'inner'
pd.concat([df1, df2, df3], join = 'inner')
# 인덱스 재지정 → ignore_index=True
pd.concat([df1, df2, df3], join = 'inner', ignore_index = True)
1.6.2 merge
- pd.merge(left, right, on = 기준 컬럼, how = 연결방법)
- 공통된 열 기준으로 데이터프레임이 연결됨
- 2개의 데이터프레임을 연결함
# name 컬럼을 기준으로 연결
pd.merge(df7, df8, on = 'name')
# 공통된 데이터만으로 연결 (default) → how = 'inner'
pd.merge(df7, df8, on = 'name', how = 'inner')
# 모든 행으로 연결 → how = 'outer'
pd.merge(df7, df8, on = 'name', how = 'outer')
# 왼쪽 데이터프레임 기준으로 연결 → how = 'left'
pd.merge(df7, df8, on = 'name', how = 'left')
# 오른쪽 데이터프레임 기준으로 연결 → how = 'right'
pd.merge(df7, df8, on = 'name', how = 'right')
1.7 행과 열의 형태 변형
1.7.1 melt
- df.melt() / pd.melt(df)
- 행을 열로 보내기
✔ 모든 열을 melt하여 행을 열로 변경

df.melt()
✔ 고정할 컬럼을 지정하여 melt → id_vars = 열이름 리스트
df.melt(id_vars = 'name') # 1개의 열
df.melt(id_vars = ['name', 'kor']) # 2개 이상의 열
✔ 행으로 위치를 변경할 열 지정 → value_vars = 열이름 리스트
df.melt(id_vars = 'name', value_vars = 'kor')
✔ 컬럼명 변경하기
- var_name = 컬럼명 : value_vars로 행으로 변경한 열 이름
- value_name = 컬럼명 : value_vars의 데이터를 저장한 열 이름

1.7.2 pivot
- df.pivot(index = 인덱스로 사용할 컬럼, columns = 컬럼으로 사용할 컬럼, values = 값으로 사용할 컬럼)
- 열을 행으로 보내기

df.pivot(index = 'name', columns = 'subject', values = 'score')
1.7.3 transpose()
- df.transpose()
- 행과 열 바꾸기

1.8 피벗테이블
- 피벗테이블 : 표의 데이터를 요약하는 통계표
- pd.pivot_table(df, index = , columns = , values = , aggfunc = 통계함수)
- aggfunc의 디폴트 : mean(평균)

# [item,color], size별 재고 합계
df.pivot_table(index = ['item', 'color'], columns = 'size', values = 'inventory', aggfunc = 'sum')
- 특정 값으로 결측치 처리 → fill_value = 특정값
- 피벗 테이블에 총계 추가 → margins = True
1.9 그룹화 (groupby)

✅ 그룹의 통계값 계산
→ df.groupby(그룹기준 컬럼).통계적용컬럼.통계함수
# 객실등급(Pclass)별 승선자 수를 구한 결과를 데이터프레임 df1로 만들기
df1 = df.groupby('Pclass').Survived.count().to_frame()
df1
# [+] size() : 누락값을 포함한 데이터 수 (count()는 누락값을 제외한 데이터 수)
✅ 그룹에 사용자 정의 함수 적용
→ df.groupby(그룹기준 컬럼).통계적용컬럼.agg(사용자정의함수, 매개변수들)
# 사용자 정의 함수 만들기
def my_mean(values):
return sum(values)/len(values)
# 그룹화
df.groupby(['Sex','Pclass']).Survived.agg(my_mean).to_frame()
✅ 그룹별 인덱스 출력
→ df.groupby(그룹기준컬럼).groups : 그룹 별 인덱스 (데이터 리스트) 출력
# Pclass 그룹별 인덱스
df20.groupby('Pclass').groups
[out] {1: [1, 3, 6, 11], 2: [9, 15, 20, 21], 3: [0, 2, 4, 7, 8, 10, 12, 13, 14, 16, 18, 22]}
✅ 그룹 인덱스에 해당하는 데이터프레임 출력
→ df.groupby(그룹기준컬럼).get_group(그룹인덱스) : 그룹 별 인덱스에 해당하는 데이터프레임 출력
# Pclass 그룹 출력(1등석)
df20.groupby('Pclass').get_group(1)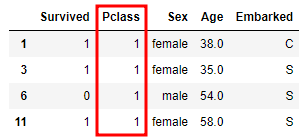
2. 멘토링
[나의 질문]
각 컬럼의 데이터를 더할 때, 결측치가 있으면 결과 값도 NaN이 되는데, NaN을 제외한 합계를 구하는 방법이 따로 있나요? 아니면 이런 경우, 결측치를 처리한 후 데이터끼리 더해야 하나요?
▶ [답변]
결측치는 데이터 전처리할 때 가장 먼저 처리해야 하는 것들 중 하나임.
그렇기에 결측치를 삭제, 대체 등 한 후에 데이터끼리의 연산을 진행해야 함.
3. 회고
Pandas와 DataFrame에 대해 공부를 했다. 데이터 분석 프로젝트를 하며 많이 사용했었는데, 이렇게 많은 기능들이 있는지 몰랐다. 매번 필요할 때 이런 기능이 있는지부터 고민하면서 구글링을 하면서 사용했었는데, 이제는 어떤 기능이 있는지 인지하고 찾아볼 수 있게 되었다.
'웅진X유데미 STARTERS > TIL (Today I Learned)' 카테고리의 다른 글
| [스타터스 TIL] 5일차.파이썬 데이터 시각화 (2) - 그래프 종류 (0) | 2023.02.11 |
|---|---|
| [스타터스 TIL] 4일차.파이썬 데이터 시각화 (1) - 기본 그래프 (0) | 2023.02.10 |
| [스타터스 TIL] 4일차.파이썬 데이터 분석 (4) - 분석 실습, value_counts, groupby (0) | 2023.02.09 |
| [스타터스 TIL] 2일차.파이썬 데이터 분석 (2) - 딕셔너리, 함수, 클래스 (0) | 2023.02.08 |
| [스타터스 TIL] 1일차.파이썬 데이터 분석 (1) - 자료형, 리스트, 튜플 (0) | 2023.02.07 |