
1. 새롭게 알게된 내용
1.1 수치형 집계함수
✅ ABS(숫자) : 숫자 절대값 출력
SELECT ABS(-10); -- [OUT] 10
✅ 소수점 올림 / 내림
- CEILING(숫자) : 올림
- FLOOR(숫자) : 내림
-- 소수점 올림
SELECT CEILING(30.75); -- [OUT] 31
SELECT CEILING(40.25); -- [OUT] 41
-- 소수점 내림
SELECT FLOOR(30.75); -- [OUT] 30
SELECT FLOOR(40.25); -- [OUT] 40
✅ ROUND(숫자, 자릿수) : 소수점 반올림
SELECT ROUND(30.75, 1); -- [OUT] 30.8
SELECT ROUND(100.925, 2); -- [OUT] 100.93
✅ 큰 수, 작은 수 출력
- GREATEST(숫자1, 숫자2, ...)
- LEAST(숫자1, 숫자2, ...)
-- 큰 수 출력
SELECT GREATEST(29, -100, 34, 8, 25); -- [OUT] 34
SELECT GREATEST("windows.com", "microsoft.com", "apple.com"); -- [OUT] windows.com
-- 작은 수 출력
SELECT LEAST(29, -100, 34, 8, 25); -- [OUT] -100
SELECT LEAST("windows.com", "microsoft.com", "apple.com"); -- [OUT] apple.com
1.2 날짜 집계함수
- WEEKOFYEAR(날짜) : 해당 날짜의 주 번호 출력
- YEARWEEK(날짜) : 해당 날짜의 연도와 주 번호 출력
-- WEEKOFYEAR
SELECT WEEKOFYEAR('2021-01-05'); -- 2021년의 1주에 해당.
SELECT WEEKOFYEAR('2021-02-01'); -- 2021년의 5주에 해당.
SELECT WEEKOFYEAR('2021-12-31'); -- 2021년의 52주에 해당.
-- YEARWEEK
SELECT YEARWEEK('2021-01-01'); -- 2020년의 52주에 해당.
SELECT YEARWEEK('2021-01-05'); -- 2021년의 1주에 해당.
1.3 VIEW와 집계함수
- VIEW의 경우, 한번 생성을 하면 수정이 불가하다.
- VIEW를 조회하려면 테이블과 동일하게 SELECT 절을 활용하면 된다.
- CREATE VIEW 뷰이름 ~ : 뷰 생성
- DAYOFWEEK : 요일 반환 (1:일 ~ 7:토)
CREATE VIEW v_weekday2
AS SELECT (CASE WHEN DAYOFWEEK(orderdate) = 1 THEN 'SUN'
WHEN DAYOFWEEK(orderdate) = 2 THEN 'MON'
WHEN DAYOFWEEK(orderdate) = 3 THEN 'TUE'
WHEN DAYOFWEEK(orderdate) = 4 THEN 'WED'
WHEN DAYOFWEEK(orderdate) = 5 THEN 'THU'
WHEN DAYOFWEEK(orderdate) = 6 THEN 'FRI'
WHEN DAYOFWEEK(orderdate) = 7 THEN 'SAT'
END) AS '요일'
, COUNT(custid) AS '수량'
, SUM(saleprice) AS '판매가 합계'
FROM ORDERS
WHERE DATE_FORMAT(orderdate, '%Y-%m-%d') BETWEEN "2021-01-01" AND "2021-08-31"
GROUP BY 1
ORDER BY 3 DESC;
SELECT * FROM v_weekday2;
- CREATE OR REPLACE VIEW 뷰이름(뷰의 컬럼): 기존의 뷰를 새롭게 대체
CREATE OR REPLACE VIEW v_Weekly(Weekly, Date, MIN, MAX)
AS SELECT YEARWEEK(orderdate) AS '주'
, orderdate AS '날짜'
, MIN(saleprice) AS '최소 판매가'
, MAX(saleprice) AS '최대 판매가'
FROM ORDERS
GROUP BY 1
ORDER BY 1;
SELECT * FROM v_Weekly;
1.4 기본 통계
📌 중심 경향성

✅ 기본 통계값 + FORMAT() 함수
- 기본 통계값 출력 (SUM, AVG, MIN, MAX, VARIANCE, STD)
- FORMAT(숫자, 자릿수) : 세 자리마다 쉼표(,) 표시 / 소수점 자릿수까지 출력
SELECT C.USERNAME AS '고객 이름'
, COUNT(O.ORDERID) AS '주문 횟수'
, FORMAT(SUM(O.SALEPRICE), 0) AS '주문금액 합계'
, FORMAT(AVG(O.SALEPRICE), 0) AS '주문금액 평균'
, FORMAT(MIN(O.SALEPRICE), 0) AS '주문금액 최소값'
, FORMAT(MAX(O.SALEPRICE), 0) AS '주문금액 최댓값'
, FORMAT(VARIANCE(O.SALEPRICE), 0) AS '분산'
, FORMAT(STD(O.SALEPRICE), 0) AS '표준편차'
FROM ORDERS O
LEFT JOIN CUSTOMER C
ON O.CUSTID = C.CUSTID
GROUP BY 1
ORDER BY 3 DESC;
✅ 사분위수 구하기
1) 전체 SALEPRICE를 하나의 ROW로 결합한다.
2) 전체 수의 각 사분위수에 해당하는 위치(인덱스)를 구한다.
3) 각 사분위수의 위치에 해당하는 가격을 구한다.
-- 1) SALEPRICE를 하나의 ROW로 결합
SELECT GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ',') AS '전체 가격 나열'
FROM Orders;
-- [OUT] 7500,8000,8000,15000,18000,18000,20000,20000,20000,23500,23500,32000,32000,35000,44000,44000
-- 2) 전체 수의 각 사분위수에 해당하는 위치(숫자)를 찾는다
-- 총 16개의 데이터가 있음
SELECT COUNT(SALEPRICE)
FROM ORDERS;
SELECT 25/100 * COUNT(SALEPRICE) AS '25%'
, 50/100 * COUNT(SALEPRICE) AS '50%'
, 75/100 * COUNT(SALEPRICE) AS '75%'
FROM ORDERS;
-- 3) 사분위수에 해당하는 가격을 찾는다
SELECT MIN(SALEPRICE) AS '최솟값'
, SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ','), ',', (25/100 * COUNT(SALEPRICE))), ',', -1) AS '25%'
, SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ','), ',', (50/100 * COUNT(SALEPRICE))), ',', -1) AS '25%'
, AVG(SALEPRICE) AS '평균값'
, SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ','), ',', (75/100 * COUNT(SALEPRICE))), ',', -1) AS '25%'
, MAX(SALEPRICE) AS '최댓값'
FROM ORDERS;
1.5 순위 함수
| 함수 | 설명 | 예시 |
| RANK(속성) | 공동 순위만큼 건너뜀 | 1, 2, 2, 4, 5 |
| DENSE_RANK(속성) | 공동 순위를 뛰어넘지 않음 | 1, 2, 2, 3, 4 |
| ROW_NUMBER(속성) | 공동 순위를 무시함 | 1, 2, 3, 4, 5 |
✅ RANK() OVER (ORDER BY 컬럼명)
-- 도서 주문 가격별 랭킹
SELECT B.bookname
, RANK() OVER (ORDER BY O.SALEPRICE) AS RANKING
FROM BOOK B, ORDERS O
WHERE B.BOOKID=O.BOOKID
GROUP BY 1;
✅ DENSE_RANK() OVER (ORDER BY 컬럼명)
-- 도서 주문 가격별 랭킹
SELECT B.bookname
, DENSE_RANK() OVER (ORDER BY O.SALEPRICE) AS RANKING
FROM BOOK B, ORDERS O
WHERE B.BOOKID=O.BOOKID
GROUP BY 1;
✅ ROW_NUMBER() OVER (ORDER BY 컬럼명)
-- 도서 주문 가격별 랭킹
SELECT B.bookname
, ROW_NUMBER() OVER (ORDER BY O.SALEPRICE) AS RANKING
FROM BOOK B, ORDERS O
WHERE B.BOOKID=O.BOOKID
GROUP BY 1;
✅ PARTITION BY 활용 예시
-- 주문 가격별 고객의 랭킹
-- PARTITION BY : 특정 컬럼 별 순위를 매길 때 사용
-- ORDER BY : 순위를 매길 컬럼 지정
SELECT B.bookname,
O.CUSTID,
ROW_NUMBER() OVER (PARTITION BY O.CUSTID ORDER BY O.SALEPRICE) AS RANKING
FROM BOOK B, ORDERS O
WHERE B.BOOKID=O.BOOKID
GROUP BY 1;
✅ GROUP BY 컬럼명 WITH ROLLUP
- 항목별 합계에 전체 합계가 같이 출력됨
SELECT SUBSTRING(address, 1, 12) as 지역,
Bookname,
COUNT(*) 수량
FROM Customer C, Book B, Orders O
WHERE O.bookid = B.bookid AND C.custid = O.custid
GROUP BY address, bookname WITH ROLLUP
HAVING address IS NOT NULL
ORDER BY username ASC, bookname DESC;
2. 멘토링
강사님과 멘토링 시간에 다양한 SQL 예제를 풀어보았다.
강의만을 듣는 것보다 이렇게 직접 예제를 풀어보니 훨씬 이해가 잘 되어서 마지막 SQL 수업을 잘 마무리해서 만족스럽다 :)
2.1 고객별 총 주문횟수, 총구매액, 평균구매액, 최소/최대구매액 구하기
# 구매하지 않은 고객 포함하기
# 구매하지 않은 고객은 집계 결과 0으로 표현하기
# 총 구매액 순으로 순위 매기기 (RANK)
나는 CASE WHEN 구문을 활용해서 NULL 값이면 0을 출력하도록 조건을 걸었다.
강사님 쿼리를 보니 IFNULL()을 사용했는데, 훨씬 간단하다.
-- 내가 작성한 쿼리 (CASE WHEN 구문 활용)
SELECT C.USERNAME AS '이름'
, COUNT(O.ORDERID) AS '총 주문횟수'
, (CASE WHEN SUM(O.SALEPRICE) IS NULL THEN 0 ELSE SUM(O.SALEPRICE) END) AS '총 구매액'
, (CASE WHEN AVG(O.SALEPRICE) IS NULL THEN 0 ELSE AVG(O.SALEPRICE) END) AS '평균 구매액'
, (CASE WHEN MIN(O.SALEPRICE) IS NULL THEN 0 ELSE MIN(O.SALEPRICE) END) AS '최소 구매액'
, (CASE WHEN MAX(O.SALEPRICE) IS NULL THEN 0 ELSE MAX(O.SALEPRICE) END) AS '최대 구매액'
, RANK() OVER (ORDER BY SUM(O.SALEPRICE) DESC) AS RANKING
FROM CUSTOMER AS C
LEFT JOIN ORDERS AS O
ON C.CUSTID = O.CUSTID
GROUP BY 1;
-- 선생님 쿼리 (IFNULL 구문 활용)
SELECT C.USERNAME AS '이름'
, COUNT(O.ORDERID) AS '총 주문횟수'
, IFNULL(SUM(O.SALEPRICE), 0) AS '총 구매액'
, IFNULL(AVG(O.SALEPRICE), 0) AS '평균 구매액'
, IFNULL(MIN(O.SALEPRICE), 0) AS '최소 구매액'
, IFNULL(MAX(O.SALEPRICE), 0) AS '최대 구매액'
, RANK() OVER (ORDER BY SUM(O.SALEPRICE) DESC) AS '순위'
FROM CUSTOMER AS C
LEFT JOIN ORDERS AS O
ON C.CUSTID = O.CUSTID
GROUP BY 1;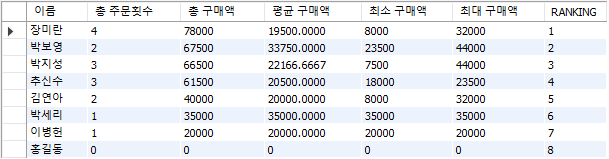
2.2 고객별 saleprice 랭킹
- RANK () OVER(PARTITION BY 컬럼명 ORDER BY 컬럼명) 활용
SELECT c.username
, b.bookname
, o.saleprice
, RANK() OVER (PARTITION BY C.USERNAME ORDER BY O.SALEPRICE) AS '순위'
FROM orders o, customer c, book b
WHERE o.custid=c.custid AND o.bookid=b.bookid;
2.3 지역 - 도서 별 판매 수량 / 지역 별 판매수량 소계
- WITH ROLLUP 활용하여 그룹화한 컬럼 별로 소계 구하기
- IFNULL을 이용하여 소계 컬럼의 데이터를 '-----소계-----'로 출력
- ⭐ 도서명을 IFNULL로 구했기 때문에, GROUP BY엔 2, 또는 '도서명'으로 입력하면 '-----소계-----'가 출력이 되지 않음
→ 컬럼명(B.bookname)으로 GROUP BY에 입력해야 함!
SELECT SUBSTRING_INDEX(address, ' ', 1) AS '지역'
, IFNULL(B.bookname, '-----소계-----') AS '도서명'
, COUNT(*) AS '판매수량'
, SUM(O.saleprice) AS '판매금액'
FROM CUSTOMER C, ORDERS O, BOOK B
WHERE C.custid = O.custid
AND O.bookid = B.bookid
GROUP BY 1, B.bookname WITH ROLLUP;
3. 회고
오늘부로 SQL 강의가 끝이 났다. 파이썬에 비해 매우 짧은 시간이었지만, 내가 어느정도 SQL 기초가 있어서 그런지 다시 한번 상기한다는 생각으로 강의를 수강하니 훨씬 수월했다.
파이썬처럼 SQL도 배운 것을 활용할 수 있는 실습을 많이 했으면 좋을텐데, 실습이 많이 없어서 아쉬웠다. 그래도 이후 교육에서 다시 SQL을 오프라인으로 배우고 활용한다고 하니 그 때 적극적으로 활용해볼 수 있지 않을까 싶다!
다음주부터 R 강의가 시작되는데, R은 ADsP 자격증 시험 때 맛보기만 해서 잘 알지 못한다. SQL 강의처럼 짧지만 알차게 배워봐야지 :)
'웅진X유데미 STARTERS > TIL (Today I Learned)' 카테고리의 다른 글
| [스타터스 TIL] 12일차.기초부터 익히는 R (2) - R 연산자, 조건문, 반복문, 함수, 시각화 (0) | 2023.02.21 |
|---|---|
| [스타터스 TIL] 11일차.기초부터 익히는 R (1) - R 자료 구조, 변수, 함수, 패키지 (0) | 2023.02.20 |
| [스타터스 TIL] 9일차.SQL을 통한 데이터활용과 분석 (2) - 기본 문법 (0) | 2023.02.16 |
| [스타터스 TIL] 8일차.SQL을 통한 데이터활용과 분석 (1) - DDL, DML, WHERE절 (0) | 2023.02.16 |
| [스타터스 TIL] 8일차.파이썬 데이터 시각화 (5) - 시각화 실습 (0) | 2023.02.16 |