
4. Pandas를 사용한 시계열
4.1 Datetime Index
1) Numpy Datetime Array
- numpy의 데이터 유형 : datetime64
- Python에 내장된 datetime 객체와는 구별된다.
- 3개의 날짜 형태의 문자열을 입력한 후, dtype='datetime64' 추가하면 datetime 형식으로 지정된다.
- 'datetime64[D]' : D는 day(일)을 나타낸다.
→ 이를 통해 기본적으로 numpy가 일 수준의 날짜 정밀도를 적용했음을 알 수 있다.
- 만약, 다른 수준의 날짜 정밀도를 적용하려면 [h], [Y]를 같이 입력하면 된다.
np.array(['2016-03-15', '2017-05-24', '2018-08-09'], dtype='datetime64')
# [out] array(['2016-03-15', '2017-05-24', '2018-08-09'], dtype='datetime64[D]')
2) Numpy Date Ranges
기간 내 특정 간격의 날짜, 기간 내 모든 날짜를 출력할 수 있다.
# 2018-06-01 ~ 2018-06-22 기간 내에 7일 간격으로 날짜 출력
np.arange('2018-06-01', '2018-06-23', 7, dtype='datetime64[D]')
[out] array(['2018-06-01', '2018-06-08', '2018-06-15', '2018-06-22'], dtype='datetime64[D]')
# 1968년 ~ 1975년 기각 내에 있는 연도 출력
np.arange('1968', '1976', dtype='datetime64[Y]')
[out] array(['1968', '1969', '1970', '1971', '1972', '1973', '1974', '1975'], dtype='datetime64[Y]')
3) Pandas Datetime Index
Pandas는 datetime 객체에 대해 유연성이 있음
datetime 객체를 위한 내장 유틸리티가 많이 있음
💡 DatetimeIndex
- Pandas에는 datetime을 위한 인덱스가 존재함
- 시계열 자료를 생성하려면 인덱스를 DatetimeIndex 자료형으로 만들어야 함
- 특정한 순간에 기록된 타임스탬프(timestamp) 형식의 시계열 자료를 다루기 위한 인덱스
→ 참고 포스팅
✅ pd.date_range(시작, 요청하는 기간 갯수, 빈도)
- datetime64[ns] : Pandas는 기본값으로 10억분의 1초 수준의 정밀도를 제공함
idx = pd.date_range('7/8/2018', periods=7, freq='D')
idx
[out]
DatetimeIndex(['2018-07-08', '2018-07-09', '2018-07-10', '2018-07-11',
'2018-07-12', '2018-07-13', '2018-07-14'],
dtype='datetime64[ns]', freq='D')
✅ pd.to_datetime()
Pandas는 문자열 코드를 유추하는데 뛰어남 → 다양한 datetime 형식을 사용해도 됨
그러나 Pandas는 날짜를 미국 스타일의 날짜 형식으로 유추함
pd.to_datetime(['2/1/2018','3/1/2018'])
[out] DatetimeIndex(['2018-02-01', '2018-03-01'], dtype='datetime64[ns]', freq=None)
유럽 스타일의 날짜 형식으로 변환하고 싶으면 직접 형식을 지정해주면 된다. → format =
pd.to_datetime(['2/1/2018','3/1/2018'], format = '%d/%m/%Y')
[out] DatetimeIndex(['2018-01-02', '2018-01-03'], dtype='datetime64[ns]', freq=None)
✅ pd.DatetimeIndex() : 일반 문자열을 DatetimeIndex로 변경
idx = pd.DatetimeIndex(some_dates)
idx
[out] DatetimeIndex(['2016-03-15', '2017-05-24', '2018-08-09'], dtype='datetime64[ns]', freq=None)
✅ 데이터프레임에서 특정 값 출력
# 최근 값
df.index.max() # [out] Timestamp('2018-08-09 00:00:00')
# 최근값의 인덱스 위치
df.index.argmax() # [out] 2
# 가장 이전 값
df.index.min() # [out] Timestamp('2016-03-15 00:00:00')
# 가장 이전 값의 인덱스 위치
df.index.argmin() # [out] 0
4.2 Time Resampling
일종의 시간 빈도를 기반으로 집계를 하게 되는 점을 제외하면 groupby 연산과 매우 유사하다.
ex. 일일 데이터를 가져와 월별 데이터로 샘플링을 할 수 있다. (월 평균을 내거나 한 달 합계를 낼 수 있다)
어떻게 리샘플링을 할지 rule 매개변수를 통해 설정할 수 있다.
그리고 해당 매개변수에 어떻게 리샘플링 할지에 대한 문자열 코드를 입력하면 된다.
관련 문자열 코드는 다음을 참고하면 된다.


✅ 연간 데이터로 집계하기
아래의 코드를 통해 연간 평균 종가와 거래되는 주식의 평균 거래량을 확인할 수 있다.
# rule='A' : Yearly Means
df.resample(rule='A').mean()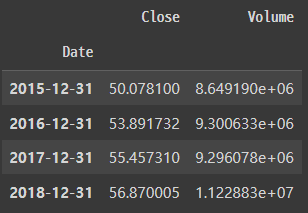
✅ 사용자 고유 샘플링 함수
우리가 직접 사용자 고유 샘플링 함수를 생성하여 사용할 수 있다.
def first_day(entry):
"""
Returns the first instance of the period, regardless of sampling rate.
"""
if len(entry): # handles the case of missing data
return entry[0]
# 각 연도의 첫번째 거래량 출력
# 인덱스는 신경쓰지 말 것!
df.resample(rule='A').apply(first_day)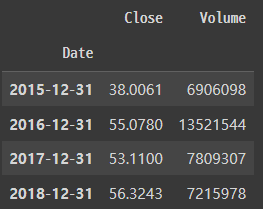
✅ 그래프 그리기
- 연도 별 최대 종가 시각화
df['Close'].resample('A').mean().plot.bar(title='Yearly Mean Closing Price for Starbucks');
- 월 별 최대 종가 시각화
# resample('M') : 월말 빈도
title = 'Monthly Max Closing Price for Starbucks'
df['Close'].resample('M').max().plot.bar(figsize=(16,6), title=title,color='#1f77b4');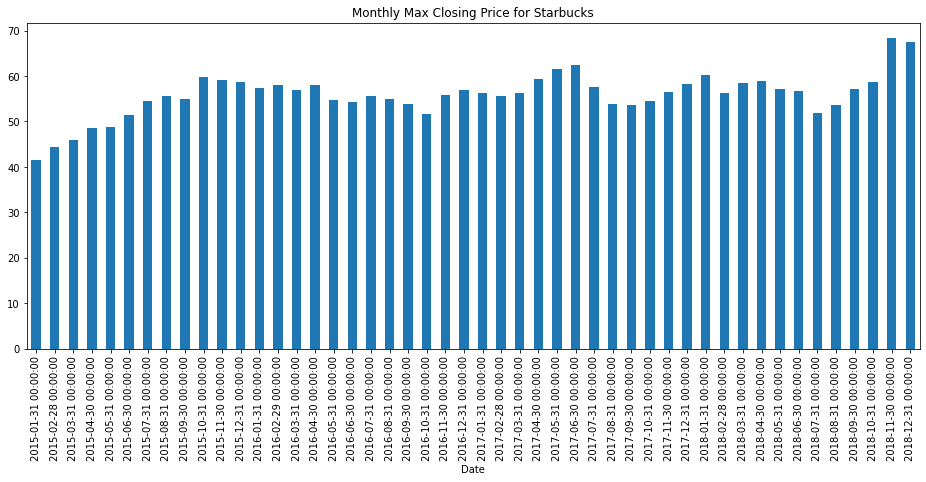
4.3 Time Shifting
모든 데이터를 위 또는 아래로 시계열 인덱스를 따라 이동시켜야 할 때가 있다. 이 때 사용할 Pandas 내장 메소드를 알아보자.
1) shift() forward
월, 연도와 같은 기간에 관계 없이 주어진 행 수에 대해 전체 Date 인덱스를 하나씩 밑으로 이동해보자.
모든 데이터를 아래로 이동시켰기 때문에 첫 데이터에 빈 데이터가 추가되며 마지막 정보는 잃어버린다.
⭐ 인덱스는 그대로 있으며 데이터만 이동한다.
df.shift(1).head()
# 마지막 정보를 잃어버리게 된다.
df.shift(1).tail()
2) shift() backwards
전체 Date 인덱스를 하나씩 위로 이동해보자.
모든 데이터를 위로 이동시켰기 때문에 첫 데이터는 잃게 되며 마지막 데이터에 빈 데이터가 추가된다.
⭐ 인덱스는 그대로 있으며 데이터만 이동한다.
df.shift(-1).head()
df.shift(-1).tail()
3) 빈도를 설정하여 인덱스 이동
- freq : 입력할 경우 인덱스가 이동하게 됨
- freq = 'M' : 인덱스를 1달만큼 이동
- periods : 이동할 기간 설정
df.shift(periods=1, freq='M').head()
16-09 기간/데이터 쉬프트 (shift)
####DataFrame.shift(periods=1, freq=None, axis=0, fill_value=NoDefault.no_default) ##개요 `shift`메서드는…
wikidocs.net
4.4 Rolling and Expanding
시계열 데이터의 일반적 프로세스는 이동평균을 기반으로 한다.
따라서 우리는 데이터를 window로 분할하고, 각 window에 대해 집계함수를 계산한다.
이 방식으로 이동 평균을 구할 수 있다.
1) Rolling
- .rolling() : 이동평균 구하기
- window = 7 : 일 단위 / 7일 간의 이동 평균 / 7일마다 평균을 구하고 7일동안 이동하며 계산
- 처음 6개는 NaN 값 : 평균을 구하려는 7개의 값이 없기 때문이다.
df.rolling(window=7).mean().head(15)
시간 별 종가(close) 그래프와 이동 평균 그래프를 함께 나타내보자.
주황색 그래프 : 30일 간의 이동 평균 (처음 29일 간의 데이터가 없음)
# 월 별 이동 평균
df['Close: 30 Day Mean'] = df['Close'].rolling(window=30).mean()
# 그래프 그리기
df[['Close','Close: 30 Day Mean']].plot(figsize=(12,5)).autoscale(axis='x',tight=True);
2) Expanding
롤링 window에 해당하는 날짜 값을 계산하는 대신 시계열의 시작점부터 계산을 하고 싶을 때 사용한다.
7일, 30일씩 각 시점마다 이동하는 대신에 이전에 나온 모든 데이터의 평균 값을 계산하여 그래프로 보여준다.
그렇기 때문에 그래프를 보면 점점 수평을 이루기 시작한다. (더 많은 데이터를 가지고 있기 때문에)
하나의 행을 더 추가한다고 해서 평균이 그렇게 많이 이동하지 않는다.
오른쪽 상단에 위치한 마지막 지점은 전체 데이터프레임의 모든 행에 대한 평균값이다.
# min_periods : 시작할 최소 기간의 수
df['Close'].expanding(min_periods=30).mean().plot(figsize=(12,5));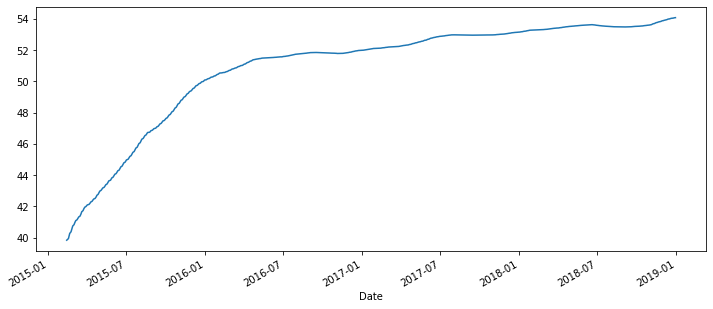
4.5 시계열 데이터 시각화
1) 제목, 축 라벨 추가
# 종가(close) 그래프 그리기
title='Starbucks Closing Stock Prices'
ylabel='Closing Price (USD)'
xlabel='Closing Date'
ax = df['Close'].plot(figsize=(12,6),title=title)
ax.autoscale(axis='x',tight=True) # 그래프를 x축 기준으로 스케일 (그래프와 축 사이의 공백을 없앰)
ax.set(xlabel=xlabel, ylabel=ylabel); # x, y축 레이블 지정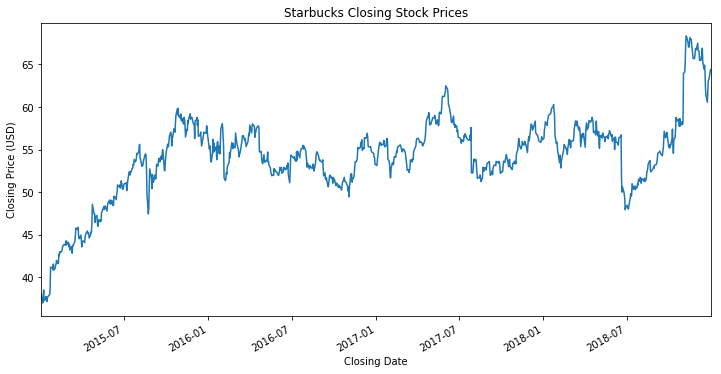
2) x축 범위 설정
→ 범위 슬라이싱, xlim 매개변수 활용
## 2017년의 데이터만 시각화하기
# 1. df['Close'] 시리즈를 인덱싱하여 범위 슬라이싱
df['Close']['2017-01-01':'2017-12-31'].plot(figsize=(12,4)).autoscale(axis='x',tight=True);
# 2. xlim 매개변수를 활용하여 범위 설정
df['Close'].plot(figsize=(12,4),xlim=['2017-01-01','2017-12-31']);

3) y축 범위 설정
→ ylim 매개변수 활용
# Y축의 범위를 설정하기
df['Close'].plot(figsize=(12,4),xlim=['2017-01-01','2017-12-31'],ylim=[51,63]);
4) 그래프 선 색상 및 선 스타일
# ls : 선 스타일
# c : 선 색상
df['Close'].plot(xlim=['2017-01-01','2017-03-01'],ylim=[51,57],ls='--',c='r');
5) x축 눈금 간격 설정
→ set_major_locator : x축 눈금의 위치를 설정
# 1. 선 그래프 그리기
ax = df['Close'].plot(xlim=['2017-01-01','2017-03-01'],ylim=[51,57], figsize = (12, 5))
# 2. 기본 x축 레이블 지우기
ax.set(xlabel='')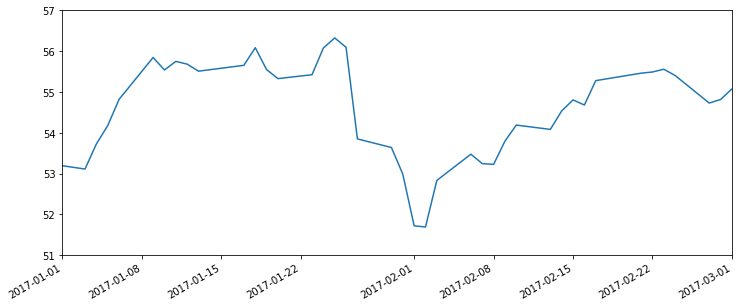
1월 29일이 표현되지 않고 1월 22일 다음에 바로 2월 1일이 있다.
그 이유는 우리는 지금 7일 단위로 이동하고 있는데 Pandas는 제자리로 가서 매우러 1일이 시간되는 위치를 표시하려고 하기 때문이다.
그래서 직접 x축의 간격을 설정해야 한다.
# 1. 선 그래프 그리기
ax = df['Close'].plot(xlim=['2017-01-01','2017-03-01'],ylim=[51,57], figsize = (12, 5))
# 2. 기본 x축 레이블 지우기
ax.set(xlabel='')
# 3. x축 간격 재설정
# WeekdayLocator : 일일 데이터이므로
# byweekday=0 : 일주일의 시작을 월요일로 설정 (0 : 월요일)
ax.xaxis.set_major_locator(dates.WeekdayLocator(byweekday=0))
6) 날짜 포맷팅
→ set_major_formatter : x축 눈금의 형식을 지정


ax = df['Close'].plot(xlim=['2017-01-01','2017-03-01']
, ylim=[51,57]
, title='2017 Starbucks Closing Stock Prices'
, figsize = (12, 5))
ax.set(xlabel='')
# set_major_locator : x축 눈금의 위치를 설정
# set_major_formatter : x축 눈금의 형식을 지정
ax.xaxis.set_major_locator(dates.WeekdayLocator(byweekday=0))
ax.xaxis.set_major_formatter(dates.DateFormatter("%a-%B-%d")) # 날짜 형식 변경
7) 주요 축, 보조 축 설정
→ set_major_locator : 주요 축 설정
→ set_minor_locator : 보조 축 설정
ax = df['Close'].plot(xlim=['2017-01-01','2017-03-01'],ylim=[51,57],rot=0,title='2017 Starbucks Closing Stock Prices' , figsize = (12, 5))
ax.set(xlabel='')
# 주요 축 설정
ax.xaxis.set_major_locator(dates.WeekdayLocator(byweekday=0))
ax.xaxis.set_major_formatter(dates.DateFormatter('%d'))
# 보조 축 설정
ax.xaxis.set_minor_locator(dates.MonthLocator()) # 월 이름
ax.xaxis.set_minor_formatter(dates.DateFormatter('\n\n%b')) # 축약된 월 이름
8) 그리드 추가
→ grid(True) : 그리드 추가하기

5. Statsmodels를 이용한 시계열 자료 분석
5.1 statsmodels 라이브러리
시계열 예측을 하는데 사용하는 주 라이브러리로
다양한 통계 모형의 추정과 통계 검정, 통계적 데이터 탐색 등을 다루는 클래스와 함수를 제공하는 파이썬 모듈이다.
✅ 시계열 데이터
- 추세 : 시계열 데이터는 경향성이 있는 경우가 있다.
- 계절성 : 반복적 추세 (잘 알려진 주기이며 매년 반복된다)
- 순환적 요소 : 반복성이 없는 요소
✅ 호드릭-프레스콧 필터
yt로 표현되는 시계열 데이터를 추세요소인 tt와 순환 요소인 Ct로 분해한다.
yt=τt+ct
데이터의 추세 요소와 순환 요소 2가지 요소를 찾아 분해한다.
이 두 요소는 2차 손실 함수를 최소화하는 값으로 결정된다.
여기서 람다는 평활화 계수이다.

이 식이 호드릭-프레스콧 필터가 두 요소를 추출해내는데 사용되는 식으로 이를 최소화하여 찾는다.
람다값은 추세 요소의 증가율 변동폭을 조절한다.
람다값은 데이터에 따라 사용하기 좋은 값들이 이미 알려져 있다. 분기별 데이터의 람다 값은 1600, 연간 데이터에는 6.25, 월간 데이터에는 129,600이 추천된다.
✔ tsa : 시계열 분석 모듈
✔ hp_filter : 호드릭-프레스콧 필터
from statsmodels.tsa.filters.hp_filter import hpfilter
순환요소, 추세요소 2개의 데이터를 반환하기 때문에 반환값인 튜플을 언패킹한다.
gdp_cycle, gdp_trend = hpfilter(df['realgdp'], lamb=1600)
추세요소를 trend 컬럼으로 추가하고 추세요소와 실제 추세값을 시각화해보자.
df[['trend','realgdp']].plot(figsize=(12,8)).autoscale(axis='x',tight=True);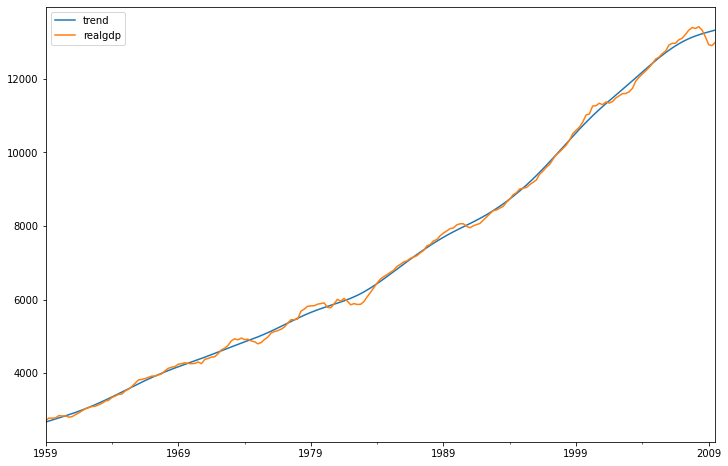
후반으로 갈수록 그래프의 차이가 있어서 확대해서 확인해보자.
→ 2008년에 시작한 대불황으로 인해 몇 년간 추세를 따르지 않는다.
df[['trend','realgdp']]['2005-01-01':].plot(figsize=(12,8)).autoscale(axis='x',tight=True);
5.2 ETS 모델 (Error/Trend/Seasonality Models)
✅ ETS 모델
오차(E), 추세(T), 계절성(S)의 줄임말로 지수평활법과 ETS 분해, 추세 모형과 같이 다양한 모델들을 포함하는 일반적 표현이다.
오차(E), 추세(T), 계절성(S) 세 요소를 더하거나 곱하거나 일부를 사용하지 않고 데이터를 평활화한다.
모델에 따라 주요 요소에 기반하여 데이터에 맞는 일반화 모형을 만들 수 있다.
✅ ETS 모델의 종류
덧셈 모델 : 추세가 선형에 더 가깝고 계절성이 거의 일정해보일 때 적용
곱셈 모델 : 지수적 증감하는 경우와 같이 비선형적으로 증가 혹은 감소하는 경우에 적용
statsmodels의 ETS 분해를 실행하면 datetime을 x축으로 그려진 4개의 플롯들을 리턴한다.
- 첫번째 : 전체 그래프
- 두번째 : 추세 그래프 → 데이터의 전반적인 상승세 또는 하강세를 보여줌 (추세가 지수형인지 선형인지 확인 가능)
- 세번째 : 계절성 그래프 → 추세 요소를 제거한 계절성 요소
- 네번째 : 잔차(오차)항 그래프 → 추세, 계절성으로 설명되지 않는 잔차, 오차가 잔차항에 표시 (잡음)
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(airline['Thousands of Passengers'], model='multiplicative')
result.plot();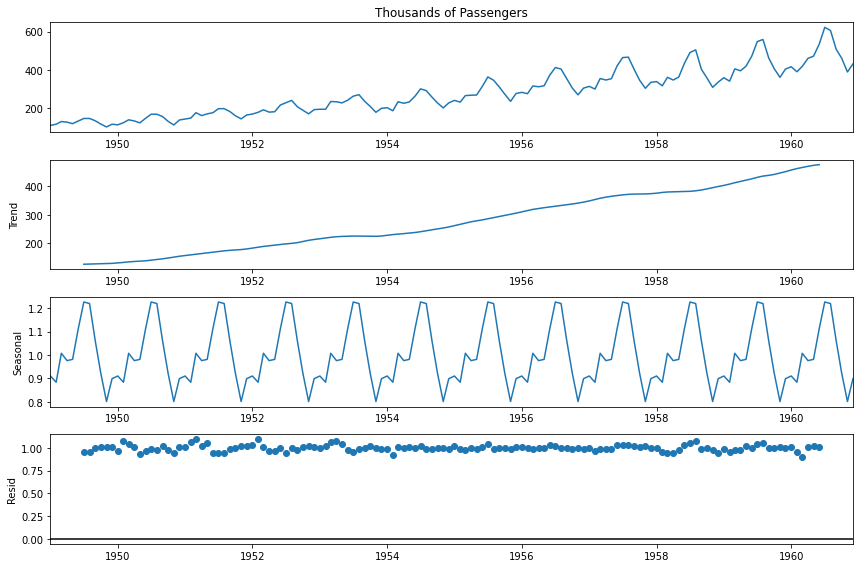
총 4개의 그래프를 각각 하나씩 그릴 수 있다.
# 가운데에 trend, seasonal, resid 입력
result.trend.plot();
5.3 EWMA (지수 가중 이동 평균)
1) SMA (단순 이동 평균)
📌 단순 이동 평균의 문제점
✔ 전체 모델이 같은 이동 평균 기간으로 제한된다는 것이다.
→ 데이터셋의 길이가 길더라도 데이터셋 전체에 똑같이 적용이 되어 하나의 이동 평균 기간 밖에 적용할 수 없다.
→ 최근의 데이터에 이동 평균이 가중되길 원할 때는 EWMA(지수 가중 이동 평균)를 사용할 수 있다.
✔ 짧은 이동 평균 기간을 이용하면 잡음이 커질 수 있다.
✔ 이동평균 기간만큼 시차가 생기게 된다.
✔ 평균을 함으로써 원래 데이터의 최댓값과 최솟값에 못 미치는 값을 보인다.
✔ 실제로 미래 변동에 대해 어떠한 정보도 지니고 있지 않다.
→ 단순히 현재 데이터의 일반적인 추세만을 보여주며 극단적으로 크거나 작은 값은 단순 이동 평균을 왜곡시킬 수 있다.
# 6개월 이동 평균 컬럼
airline['6-month-SMA'] = airline['Thousands of Passengers'].rolling(window=6).mean()
# 12개월 이동 평균 컬럼
airline['12-month-SMA'] = airline['Thousands of Passengers'].rolling(window=12).mean()
airline.plot(figsize = (10, 8));
2) EWMA (지수 가중 이동 평균)
가장 최근의 값에 적용되는 가중치는 매개변수에 의해 결정되며 이동 평균 기간에 따라서도 변화한다.
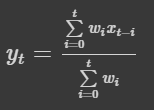
특정 시간 t에 대한 출력 값은 yt 값과 입력 값인 xt, 가중치인 wi가 있다.
i = 0에서 t로 변할 때 wi 값도 변하게 된다.
❓ 지수 가중 이동 평균을 할 때, 입력 값을 어떻게 해서 어떤 출력 값을 얻을 수 있을까?
❓ 데이터의 처음부터 끝까지 변하는 값인 가중치 항은 어떻게 결정할 수 있을까?
▶ 이 값은 .ewm() 메소드에 넣는 adjust 매개변수의 값에 따라 결정된다.

실제 출력 값인 yt는 xt+(1−α)xt−1+(1−α)2xt−2+...+(1−α)tx01+(1−α)+(1−α)2+...+(1−α)t까지 계속되는 값이 들어가고 분모에는 분자의 계수인 가중치들의 합이 들어간다. wi를 (1-α)t로 바꾼 것과 같다
가중치는 시계열에서 멀어질수록 감소하게 된다
→ α가 0부터 1사이의 값을 갖기 때문이다. 이 값들을 거듭제곱하면 할수록 더 작은 숫자가 된다.
→ 그렇기에 데이터가 오래될수록 더 작은 가중치가 곱해지는 것을 알 수 있다.
Pandas에서는 α 값이 3가지 방법으로 정해질 수 있다.
- span : n일 이동 평균 (이동 평균 기간 설정)
- com : c=(s−1)/2와 같은 값으로 span과 역관계를 갖는다.
- halflife : 지수적 가중치가 반으로 줄어드는데 걸리는 기간
- alpha : 평활화 정도
✔ewm 메소드 : 지수 가중 함수들을 제공함
✔ span : 기간 설정 / 12개월(1년)
airline['EWMA12'] = airline['Thousands of Passengers'].ewm(span=12,adjust=False).mean()
시작 부분과 끝 부분이 조금 다르게 보인다.
계절성 추세가 끝부분으로 갈수록 더 잘 보인다. → 오래된 자료보다 최신의 자료에 더 큰 가중치를 두었기 때문
# 실제 추세선과 EWMA 추세선 비교
airline[['Thousands of Passengers','EWMA12']].plot(figsize = (10, 8));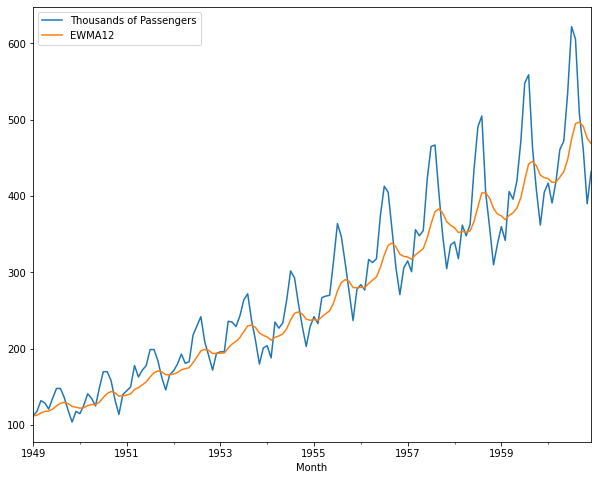
SMA와 EWMA를 비교해보면 EWMA가 좀 더 실제 추세선과 비슷한 것을 확인할 수 있다.
airline[['Thousands of Passengers','EWMA12','12-month-SMA']].plot(figsize=(12,8)).autoscale(axis='x',tight=True);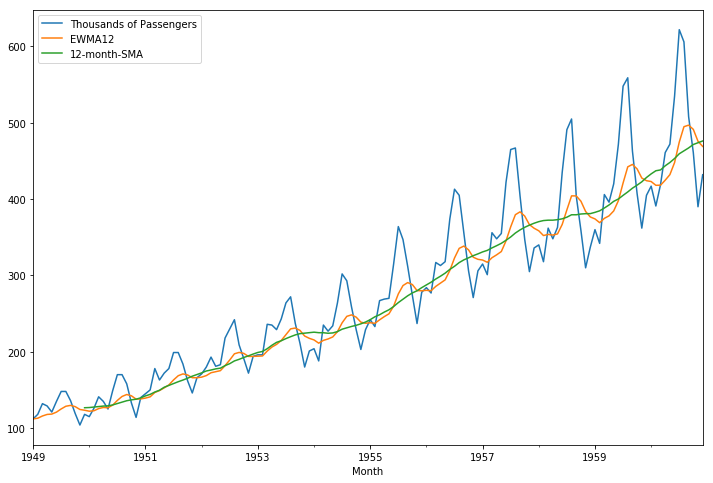
5.4 Holt-Winters Methods (홀트-윈터스 계절성 기법)
- 예측식에 더해 3개의 평활식으로 구성되어 있음
→ 수준 : l_t, 추세 요소 : b_t, 계절성 요소 : s_t
→ 각각에 대응하는 평활 매개변수 : α, β, γ
- 계절성 요소를 다루기 위한 방법
→ 덧셈 기법 : 계절성 요소가 전체 데이터에서 일정한 폭으로 나타날 때 사용
→ 곱셈 기법 : 계절적 변동폭이 데이터의 수준에 비례해 나타날 때 사용
pandas는 빈도값을 제공하지 않기 때문에 수동으로 설정해줘야 한다.
# 빈도 : 'MS' → 자료가 매 달 첫째 날이기 떄문
df.index.freq = 'MS'
df.index
[out]
DatetimeIndex(['1949-01-01', '1949-02-01', '1949-03-01', '1949-04-01',
'1949-05-01', '1949-06-01', '1949-07-01', '1949-08-01',
'1949-09-01', '1949-10-01',
...
'1960-03-01', '1960-04-01', '1960-05-01', '1960-06-01',
'1960-07-01', '1960-08-01', '1960-09-01', '1960-10-01',
'1960-11-01', '1960-12-01'],
dtype='datetime64[ns]', name='Month', length=144, freq='MS')
1) 지수 가중 이동 평균
✅ ewm() 메소드 vs SimpleExpSmoothing 메소드
→ ewm() 메소드를 활용한 지수 가중 이동 평균과 SimpleExpSmoothing 메소드를 이용해 데이터에 맞는 모형을 피팅한 값이 동일한지 확인하고자 한다.
from statsmodels.tsa.holtwinters import SimpleExpSmoothing
# span, alpha 값 설정
span = 12
alpha = 2/(span+1)
# EWMA12 컬럼 지수 가중 이동 평균
df['EWMA12'] = df['Thousands of Passengers'].ewm(alpha=alpha,adjust=False).mean()
df.head()
- smoothing_level : alpha와 값이 같음 (단일 지수 평활에 들어가는 값)
- optimized : 설정되지 않은 값들을 자동으로 최적화
- optimized=False라고 설정했을 때, 결과값이 하나씩 밀림 → shift로 수정
df['SES12']=SimpleExpSmoothing(df['Thousands of Passengers']).fit(smoothing_level=alpha,optimized=False).fittedvalues.shift(-1)
df.head()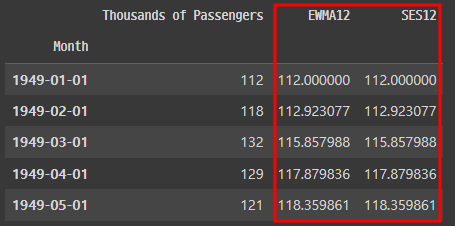
▶ SimpleExpSmoothing의 결과가 지수 가중 이동 평균의 값과 동일하다는 점을 확인할 수 있다.
2) 이중 지수 평활법 (홀트 기법)
추세를 나타내는 새로운 평활 매개변수인 베타가 추가됨
알파를 이용해 정의되어 특정 시간 t에서의 수준을 나타내는 l_t와 전반적 추세로부터 정의되는 b_t가 있다.
특정 시점 t로부터 h만큼 지난 미래의 값인 y_t+h = l_t + hb_t가 된다.
홀트 기법은 시계열 데이터를 실질적인 값인 수준 요소와 추세, 2가지 요소로 분리하는 개념
아직 계절성 요소를 반영하지 않았기 때문에 예측 모델은 가장 최신의 데이터로부터 연장된 단순한 직선이다.

from statsmodels.tsa.holtwinters import ExponentialSmoothingdf.plot()
▶ 시계열 데이터가 기울어진 직선 모양의 추세를 보인다면 덧셈 모형을 사용해야 한다.
반면, 시계열 데이터가 지수적으로 증가하거나 곡선형 추세를 보인다면 곱셈 모형을 사용해야 한다.
✔ 덧셈 모형 사용 → trend='add'
df['DESadd12'] = ExponentialSmoothing(df['Thousands of Passengers'], trend='add').fit().fittedvalues.shift(-1)
df.head()
✔ 곱셈 모형 사용 → trend='mul'
df['DESmul12'] = ExponentialSmoothing(df['Thousands of Passengers'], trend='mul').fit().fittedvalues.shift(-1)
df.head()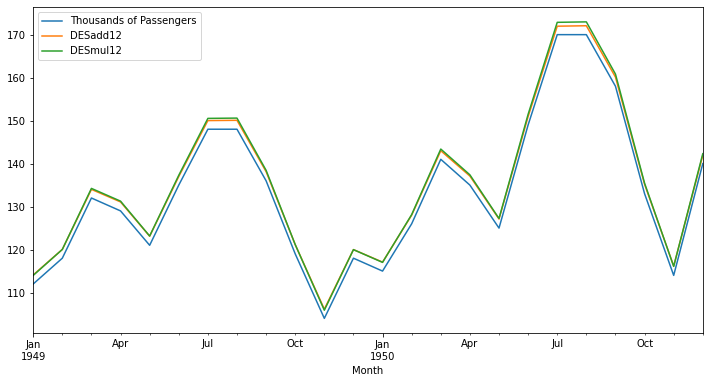
▶ 곱셈 모형이 실제 데이터에 더 가깝게 예측하고 있다 → 곱셈 모형을 사용해야 함
3) 삼중 지수 평활법 (홀트-윈터스 계절성 기법)
계절성을 표현하는 새로운 평활 매개변수인 감마가 추가된다.
계절성 요소를 나타내는 c_t라는 새로운 요소가 추가되고 감마로 표현된다.
예측 모형에 L은 주기 당 데이터 포인트의 수이다.

# 추세 : 덧셈 모형 → trend='add'
# 계절성 : 덧셈 모형 → seasonal='add'
df['TESadd12'] = ExponentialSmoothing(df['Thousands of Passengers'],trend='add',seasonal='add',seasonal_periods=12).fit().fittedvalues
# 추세 : 곱셈 모형 → trend='mul'
# 계절성 : 곱셈 모형 → seasonal='mul'
df['TESmul12'] = ExponentialSmoothing(df['Thousands of Passengers'],trend='mul',seasonal='mul',seasonal_periods=12).fit().fittedvalues
df.head()
✅ 이중 vs 삼중 지수 평활법 비교
df[['Thousands of Passengers','DESmul12','TESmul12']].iloc[:24].plot(figsize=(12,6));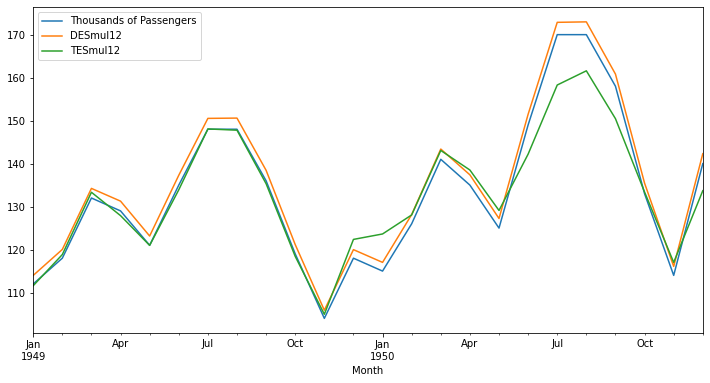
💡 회고
✔ 마무리하며..
통계적인 지식이 나와서 이해하기가 버거웠다. 그래도 엄청 통계 지식을 요구하는 게 아니라서 이해할 수 있는 선까지 공부했다.
✔ 유익한 점 & 배운점
어떤 매개변수를 사용하고 어떤 기법을 사용하느냐에 따라서 예측의 결과가 많이 달라지는 부분이 신기했으며, 각 기법 별로 특징을 명확하게 이해해야겠다는 생각이 들었다.
✔ 아쉬운 점
내일이 시험인데,,, 강의도 들어야 하고,,, 어떤 것을 선택하고 집중해야 할지 너무나 많은 고민이 들었다ㅠㅠ
강의가 많이 밀려있는 상태라 강의를 선택해서 오늘 하루종일 강의를 들었는데, 이것을 선택한 것에 대한 보상이 있길 바란다....🙏
'웅진X유데미 STARTERS > TIL (Today I Learned)' 카테고리의 다른 글
| [스타터스 TIL] 25일차.태블로 실전 트레이닝 (1) - Data Analyst, 대시보드 만들기 (0) | 2023.03.13 |
|---|---|
| [스타터스 TIL] 24일차.시계열 데이터 분석 with 파이썬 (3) - 일반 예측 모델 (0) | 2023.03.12 |
| [스타터스 TIL] 22일차.시계열 데이터 분석 with 파이썬 (1) - Numpy, Pandas, Pandas 기반 시각화 (0) | 2023.03.08 |
| [스타터스 TIL] 21일차.Tableau 고수되기 (2) - 애니메이션, 세부 수준 계산 (LOD), 고급 매핑 기술 (0) | 2023.03.07 |
| [스타터스 TIL] 20일차.Tableau 고수되기 (1) -그룹, 집합, 테이블 계산, 데이터 소스 필터 (0) | 2023.03.07 |