해당 포스팅은 AIFFEL에서 제공한 학습자료를 통해 공부한 것을 정리한 것임을 밝힙니다.

학습 목표
- 언어 모델이 발전해 온 과정을 개략적으로 파악한다.
- 기존 RNN 기법이 번역에서 보인 한계를 파악하고, 이를 개선한 Seq2seq를 이해한다.
- Seq2seq를 발전시킨 Attention에 대해 알아본다.
1. 우리가 만드는 언어 모델
언어모델(Language Model)이란, 주어진 단어들을 보고 다음 단어를 맞추는 모델이다. 즉, 단어의 시퀀스를 보고 다음 단어에 확률을 할당하는 모델이다.
언어 모델은 n-1개의 단어 시퀀스가 주어졌을 때, n번째 단어로 무엇이 올지 예측하는 확률 모델로 표현된다. 파라미터 로 모델링하는 언어 모델을 다음과 같이 표현할 수 있다.
1.1 통계적 언어 모델(Statistical Language Model)
딥러닝이 등장하기 이전에 통계적 언어 모델의 사용이 지배적이었다.
하지만 통계적 언어 모델은 '등장한 적 없는 단어나 문장에 대해 모델링을 할 수 없다.'는 단점이 있다. 데이터가 많아도 세상 모든 단어를 포함할 수 없다.
언어모델은 충분한 데이터가 없다면 범용적인 모델을 구축하기 어렵다. 그 이유는 학습 데이터에 존재하지 않는 단어와 문장에 대해서는 확률을 부여할 수 없기 때문이다. 따라서 언어 모델이 아우르는 범위를 넓히기 위해 다양한 단어를 포한하는 데이터가 필요하다. (양까지 충분하다면 정의하는 확률이 일반적이므로 더욱 좋다.)
1.2 신경망 언어 모델(Neural Network Language Model)
통계적 언어 모델의 단점을 개선한 모델인 신경망 언어 모델(NNLM)이다. NNLM의 시초는 Feed-Forward 신경망 언어 모델로, 지금의 Embedding 레이어의 아이디어인 모델이다.
희소문제(sparsity problem)란, 모델이 충분한 데이터를 관측하지 못하면 언어를 정확히 모델링 할 수 없는 문제를 말한다. 한 번도 관측하지 못한 데이터에 대해선 0에 확률을 부여한다는 것에서 문제가 발생한다.
원-핫 입력이 투사층을 거쳐가는 것은 해당 행을 읽어오는 것과 동일하다. 그래서 이 작업을 룩업 테이블(Lookup Table)이라고 한다.
출력층에서 사용되는 활성함수 Softmax를 거쳐 나온 0-1 사이 값은 해당 인덱스에 대한 확률을 의미한다.
각 단어를 일련의 Embedding 벡터로 표현한 후, 이전의 몇 개 단어를 활용하여 다음 단어를 예측하는 것은 많은 문제를 해결했다. 특히 단어 간의 유사도를 표현할 수 있게 되어 문장의 유창성이 높아졌다.
하지만 예측에 정해진 개수의 단어만 참고한다는 한계가 있어 "몇 개 단어가 들어와도 문장 단위로 처리한다"는 종류의 모델링이 필요하게 되었다. 이를 위해 고안된 것이 순환 신경망(Recurrent Neural Network, RNN)을 활용한 언어 모델이다.
2. Sequence to Sequence 문제
여러 개의 단어(Embedding)를 합쳐(Concatenate) 고정된 크기의 Weight를 Linear로 처리하는 방식은 유연성에 한계가 있었다. 단어의 개수에 무관하게 처리할 수 있는 네트워크가 필요하여 RNN을 활용한 언어 모델이 고안되었다.
RNN은 고정된 크기의 Weight가 선언되는 것은 동일하나 입력을 순차적으로 적립하는 방식을 채택하여 유동적인 크기의 입력을 처리할 수 있었다.
단어가 자체적으로 의미를 가질 수 있도록 Embedding을 도입하고, 입력의 유연성을 위해 RNN을 적용하였다. 하지만 RNN에 2가지 문제점이 있다.
① 하나의 Weight에 입력을 적립하다 보니 입력이 길어질수록 이전 입력에 대한 정보가 소실되는 기울기 소실(Vanishing Gradient) 문제가 있다. 그림에서 보면 마지막은 첫 입력인 남색의 정보가 거의 없어진 것을 볼 수 있다.
이러한 문제를 해결하기 위해 LSTM을 고안하였다.
Long Short-Term Memory (LSTM) 이해하기
[풀잎스쿨/cs231n] Lecture 10.Recurrent Neural Networks (RNN)
② 단어 단위로 입력과 출력을 순환하는 RNN 구조는 문장 생성엔 적합할지라도 번역에 사용하기는 어렵다는 문제가 있다.
[ex]
나는 -> I
나는 점심을 -> I lunch
나는 점심을 먹는다 -> I lunch eat(?)
각 언어 별로 어순이 다르기 때문에 위와 같은 문제가 발생한다.
그리고 입력의 길이와 번역의 길이가 같다는 보장도 없다. 문장을 다 읽고 번역하는 (문장 전체를 보고 나서 생성하는) 구조가 필요했다. 그래서 2014년 구글이 Sequence to Sequence (Seq2Seq) 구조를 제안하였다.
[논문] Sequence to Sequence Learning with Neural Networks
[논문 정리] Seq2seq (2): Sequence to Sequence Learning with Neural Networks
[논문 해석] Sequence to Sequence Learning with Neural Networks
[논문] Sequence to Sequence Learning with Neural Networks
seq2seq의 저자들이 단순한 RNN 대신 LSTM을 사용하고자 했던 이유는 단순한 RNN은 긴 입력에 대한 정보를 학습시키기 어렵기 때문이다.- x : Input Sequence
- y : Output Sequence
- v : 인코더의 입력 x에 대한 고정된 크기의 Representation Vector(Context Vector) 아웃풋으로서 디코더의 입력으로 사용됨
establish communication
입력 abc와 출력 def에 대해 a → d, b → e, c → f의 관계를 가진다면 입력을 cba로 뒤집어 a와 d 간의 거리를 가깝게 한다. 이 단순한 변형은 SGD가 입출력 간의 구조적 관계를 파악하는 것을 용이하게 하고 LSTM에 대해 성능을 Boost하는 효과가 있다.

시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)
Encoder는 입력 문장의 모든 단어들을 순차적으로 입력받고 모든 단어를 압축한 단 하나의 컨텍스트 벡터(Context Vector)를 만든다.
시작 토큰이 없는 경우, Decoder의 첫 입력으로 전달할 단어가 없어져 번역을 진행할 수 없다. 만약 랜덤한 단어를 입력으로 넣는 경우, 번역의 성능에 문제가 생긴다.
끝 토큰이 없는 경우, 문장의 끝을 알릴 수 없어 단어를 무한정 생성하게 된다. 온점이나 느낌표 등을 끝 토큰으로 사용하기엔 불안정한 성능을 보일 것이다.
어텐션 메커니즘(Attention)이란, 문맥을 더 잘 반영하는 벡터를 생성하는 메커니즘이다.
3. Sequence to Sequence 구현
Sequence to Sequence를 TensorFlow로 구현해보자. (데이터를 직접 다루기보다는 차원 수를 확인하는 실습을 해보자.)
RNN 계통의 레이어들은 입력값과 반환값이 설정에 따라 각양각색이다. 이번 구현에서는 입력으로 Embedding된 단어만 전달하고 (Hidden State는 전달하지 않음), 출력은 Encoder와 Decoder 별 상이하게 전달된다.
3.1 LSTM Encoder
import tensorflow as tf
class Encoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, enc_units):
super(Encoder, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.lstm = tf.keras.layers.LSTM(enc_units) # return_sequences 매개변수를 기본값 False로 전달
def call(self, x):
print("입력 Shape:", x.shape)
x = self.embedding(x)
print("Embedding Layer를 거친 Shape:", x.shape)
output = self.lstm(x)
print("LSTM Layer의 Output Shape:", output.shape)
return output
print("슝~")Embedding 레이어를 단어 사이즈와 Embedding 차원에 대해 선언한 후 tf.keras.layers.LSTM(enc_units)으로 정의한다.
TensorFlow 속 LSTM 모듈의 기본 반환 값은 최종 State 값이므로 return_sequences나 return_state 값은 따로 조정하지 않는다. (기본 : False) 이 말은 우리가 정의해 준 Encoder 클래스의 반환 값이 곧 컨텍스트 벡터(Context Vector)가 된다.
vocab_size = 30000
emb_size = 256
lstm_size = 512
batch_size = 1
sample_seq_len = 3
print("Vocab Size: {0}".format(vocab_size))
print("Embedidng Size: {0}".format(emb_size))
print("LSTM Size: {0}".format(lstm_size))
print("Batch Size: {0}".format(batch_size))
print("Sample Sequence Length: {0}\n".format(sample_seq_len))Vocab Size: 30000
Embedidng Size: 256
LSTM Size: 512
Batch Size: 1
Sample Sequence Length: 3
encoder = Encoder(vocab_size, emb_size, lstm_size)
sample_input = tf.zeros((batch_size, sample_seq_len))
sample_output = encoder(sample_input) # 컨텍스트 벡터로 사용할 인코더 LSTM의 최종 State값입력 Shape: (1, 3)
Embedding Layer를 거친 Shape: (1, 3, 256)
LSTM Layer의 Output Shape: (1, 512)

3.2 LSTM Decoder
# Encoder 구현에 사용된 변수들을 이어 사용함에 유의!
class Decoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, dec_units):
super(Decoder, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.lstm = tf.keras.layers.LSTM(dec_units,
return_sequences=True) # return_sequences 매개변수를 True로 설정
self.fc = tf.keras.layers.Dense(vocab_size)
self.softmax = tf.keras.layers.Softmax(axis=-1)
def call(self, x, context_v): # 디코더의 입력 x와 인코더의 컨텍스트 벡터를 인자로 받는다.
print("입력 Shape:", x.shape)
x = self.embedding(x)
print("Embedding Layer를 거친 Shape:", x.shape)
context_v = tf.repeat(tf.expand_dims(context_v, axis=1),
repeats=x.shape[1], axis=1)
x = tf.concat([x, context_v], axis=-1) # 컨텍스트 벡터를 concat 해준다
print("Context Vector가 더해진 Shape:", x.shape)
x = self.lstm(x)
print("LSTM Layer의 Output Shape:", x.shape)
output = self.fc(x)
print("Decoder 최종 Output Shape:", output.shape)
return self.softmax(output)
print("슝~")
Decoder는 Encoder와 구조적으로 유사하지만, 결과물을 생성해야 하므로 Fully Connected Layer가 추가되었고, 출력값을 확률로 변환해 주는 Softmax 함수도 추가되었다.
그리고 Decoder가 매 스텝 생성하는 출력은 우리가 원하는 번역 결과에 해당하므로 LSTM 레이어의 return_sequences 변수를 True로 설정하여 State 값이 아닌 Sequence 값을 출력으로 받는다.
print("Vocab Size: {0}".format(vocab_size))
print("Embedidng Size: {0}".format(emb_size))
print("LSTM Size: {0}".format(lstm_size))
print("Batch Size: {0}".format(batch_size))
print("Sample Sequence Length: {0}\n".format(sample_seq_len))Vocab Size: 30000
Embedidng Size: 256
LSTM Size: 512
Batch Size: 1
Sample Sequence Length: 3
decoder = Decoder(vocab_size, emb_size, lstm_size)
sample_input = tf.zeros((batch_size, sample_seq_len))
dec_output = decoder(sample_input, sample_output) # Decoder.call(x, context_v) 을 호출입력 Shape: (1, 3)
Embedding Layer를 거친 Shape: (1, 3, 256)
Context Vector가 더해진 Shape: (1, 3, 768)
LSTM Layer의 Output Shape: (1, 3, 512)
Decoder 최종 Output Shape: (1, 3, 30000)


Encoder가 생성한 컨텍스트 벡터 v를 Embedding 레이어를 거친 y값에 Concatnate하여 위 수식을 만족하게 된다. 이렇게 Seq2Seq를 완성하였다.
4. Attention
4.1 Bahdanau Attention
Bahdanau는 Seq2Seq의 컨텍스트 벡터가 고정된 길이로 정보를 압축하는 것이 손실을 야기한다고 주장하였다. 문장이 길어질수록 성능이 저하된다는 것이다.
이에 Encoder의 최종 State 값만을 사용하는 방식이 아닌, 매 스텝의 Hidden State를 활용해 컨텍스트 벡터를 구축하는 Attention 메커니즘을 제안한다.
[논문] NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
[😎정리글] Attention mechanism in NLP. From seq2seq + attention to BERT
[😎정리글] Attention mechanism in NLP. From seq2seq + attention to BERT
모델의 성능 향상 이외에 Attention을 활용할 수 있는 방법이 있다.
Attention Map의 시각화를 통해 모델의 안정성을 점검할 수 있고, 모델이 의도와 다르게 작동될 경우 그 원인을 찾아내는 데에 이용될 수 있다.
Sequence Labeling (ex. 품사 태깅) : x_i와 y_i의 관계를 구하는 문제
Sequence to Sequence (ex. 번역) : x_{1:n}과 동일한 의미를 가지는 y_{1:m}을 만드는 문제
4.1.1 seq2seq와 attn-seq2seq, 뭐가 다른가?

Attention이 없는 것과 있는 것의 차이는 무엇일까?
식을 보면 attention이 있는 경우엔 바로 context vector c에 첨자i가 붙어있다.

그림 왼쪽 부분은 X_j를 입력으로, y_i를 출력으로 하는 인코더-디코더 부분을 도식화한 것이다.
i는 디코더의 인덱스, j는 인코더의 인덱스이다.
context vector c에 첨자 i가 붙어 c_i가 된다는 것은 의미는 인코더가 X를 해석한 context vecter c_i는 디코더의 포지션i에 따라 다르게 표현되어야 한다.
seq2seq의 인코더가 해석한 context는 디코더의 포지션 i에 무관하게 항상 일정하였으나 attention이 가미되면 달라진다. 디코더가 현재 시점 i에서 보기에 인코더의 어느 부분j이 중요한지 확인하여 가중치를 두는데, 이 가중치가 attention이다.
가중치는 α_{ij}가 바로 인코더의 j번째 hidden state h_j가 얼마나 강조되어야 할지를 결정하는 가중치 역할을 한다. 이 가중치는 다시 디코더의 직전 스텝의 hidden state s_{i-1}와 h_j의 유사도가 높을수록 높아지게 되어 있다.

Softmax 함수의 특성으로 인해 가중치의 합이 1이 되는 위와 같은 식이 성립이 된다. Softmax 함수는 입력값을 확률값으로 변환해주는 특성이 있다.
Attn: Illustrated Attention
Softmax의 결괏값은 독립적이지 않다. RNN은 단어의 정보를 순차적으로 적립하여 Hidden State를 구축하기 때문에 순방향 RNN의 첫 단어는 그 단어의 정보만을 담고 있지만 그 이후 스텝들은 거쳐온 모든 단어의 정보를 포함하고 있다.
컨텍스트 벡터가 핵심 단어(비중이 큰 단어)에 가장 근접하게 다가서되, 주변 단어에도 각각의 비중만큼 영향을 받아 문장을 적합한 위치에 매핑하게 한다.
기존 RNN의 최종 스텝을 컨텍스트 벡터로 쓰던 방식은 항상 고정된 비중(마지막에 등장한 단어가 큰 비중)을 사용하는 셈이므로 Bahdanau의 방식보다 문맥 정보를 유연하게 반영하지 못한다.
Bahdanau 방식에서 생성된 컨텍스트 벡터는 Decoder의 이전 Hidden State와 Concatenate하여 새로운 Hidden State로 정의된다.

class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W_decoder = tf.keras.layers.Dense(units)
self.W_encoder = tf.keras.layers.Dense(units)
self.W_combine = tf.keras.layers.Dense(1)
def call(self, H_encoder, H_decoder):
print("[ H_encoder ] Shape:", H_encoder.shape)
H_encoder = self.W_encoder(H_encoder)
print("[ W_encoder X H_encoder ] Shape:", H_encoder.shape)
print("\n[ H_decoder ] Shape:", H_decoder.shape)
H_decoder = tf.expand_dims(H_decoder, 1)
H_decoder = self.W_decoder(H_decoder)
print("[ W_decoder X H_decoder ] Shape:", H_decoder.shape)
score = self.W_combine(tf.nn.tanh(H_decoder + H_encoder))
print("[ Score_alignment ] Shape:", score.shape)
attention_weights = tf.nn.softmax(score, axis=1)
print("\n최종 Weight:\n", attention_weights.numpy())
context_vector = attention_weights * H_decoder
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
W_size = 100
print("Hidden State를 {0}차원으로 Mapping\n".format(W_size))
attention = BahdanauAttention(W_size)
enc_state = tf.random.uniform((1, 10, 512))
dec_state = tf.random.uniform((1, 512))
_ = attention(enc_state, dec_state)Hidden State를 100차원으로 Mapping
[ H_encoder ] Shape: (1, 10, 512)
[ W_encoder X H_encoder ] Shape: (1, 10, 100)
[ H_decoder ] Shape: (1, 512)
[ W_decoder X H_decoder ] Shape: (1, 1, 100)
[ Score_alignment ] Shape: (1, 10, 1)
최종 Weight:
[[[0.08548453]
[0.16918306]
[0.11007968]
[0.08352093]
[0.13587408]
[0.07957311]
[0.10367552]
[0.08175867]
[0.06744781]
[0.08340254]]]
Encoder의 모든 스텝에 대한 Hidden State를 100차원의 벡터 공간으로 매핑(1, 10, 100)하고 Decoder의 현재 스텝에 대한 Hidden State도 100차원의 벡터 공간으로 매핑(1, 1, 100)하여 두 State 합으로 정의된 Score(1, 10, 1)를 구하는 예시 코드이다.
실제 단어에 적용시키면 유사한 단어에 높은 비중을 할당하게 되는데, 이것을 시각화하면 다음 그림과 같다.

4.2 Luong Attention
[Attention] Luong Attention 개념 정리
Luong의 Attention은 Bahdanau의 방식을 약간 발전시킨 형태이다.
Decoder의 현재 Hidden State를 구하기 위해 한 스텝 이전의 Hidden State를 활용하는 것은 연산적으로 비효율적이다.
Luong Attention에서는 기존 Bahdanau Attention에서 제시했던 Score Function 뿐 아니라 총 4가지의 Score Function(Dot, General, Concat, Location)을 제시하였다. 이 4가지 Score 함수 중 가장 합리적인 성능을 보이는 함수는 General 함수이다.

class LuongAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(LuongAttention, self).__init__()
self.W_combine = tf.keras.layers.Dense(units)
def call(self, H_encoder, H_decoder):
print("[ H_encoder ] Shape:", H_encoder.shape)
WH = self.W_combine(H_encoder)
print("[ W_encoder X H_encoder ] Shape:", WH.shape)
H_decoder = tf.expand_dims(H_decoder, 1)
alignment = tf.matmul(WH, tf.transpose(H_decoder, [0, 2, 1]))
print("[ Score_alignment ] Shape:", alignment.shape)
attention_weights = tf.nn.softmax(alignment, axis=1)
print("\n최종 Weight:\n", attention_weights.numpy())
attention_weights = tf.squeeze(attention_weights, axis=-1)
context_vector = tf.matmul(attention_weights, H_encoder)
return context_vector, attention_weights
emb_dim = 512
attention = LuongAttention(emb_dim)
enc_state = tf.random.uniform((1, 10, emb_dim))
dec_state = tf.random.uniform((1, emb_dim))
_ = attention(enc_state, dec_state)[ H_encoder ] Shape: (1, 10, 512)
[ W_encoder X H_encoder ] Shape: (1, 10, 512)
[ Score_alignment ] Shape: (1, 10, 1)
최종 Weight:
[[[8.4169537e-02]
[1.0438006e-04]
[2.3885055e-01]
[4.9376377e-01]
[6.6537941e-03]
[1.8763486e-02]
[8.1461348e-02]
[2.4208770e-05]
[6.9700577e-04]
[7.5511962e-02]]]
Bahdanau의 Score 함수와는 다르게 하나의 Weight만 사용하는 것이 Luong Attention의 특징이다.
어떤 벡터 공간에 매핑해주는 과정이 없기에 Weight의 크기는 단어 Embedding 크기와 동일해야 연산이 가능하다.
5. GNMT와 트랜스포머
GNMT(Google's Neural Machine Translation System)는 Bahdanau Attention을 활용한 Seq2Seq 모델이다.
Google's Neural Machine Translation System.
Residual Connection을 사용하게 되면, 정확도가 올라가고 학습 속도가 빨라진다. 그리고 Gradient Exploration / Vanishing 문제를 해결한다.
Copy Model이란, 한 번도 본 적 없는 단어에 대해서 <UNK> 토큰 처리를 하지 않고 단어를 그대로 복사하여 적당한 위치에 배치하는 모델이다.
GNMT 이후에 등장한 것이 트랜스포머(Transformer)이다. 레이어를 쌓는 구조나 Residual Connection이 트랜스포머와 굉장히 유사하다.
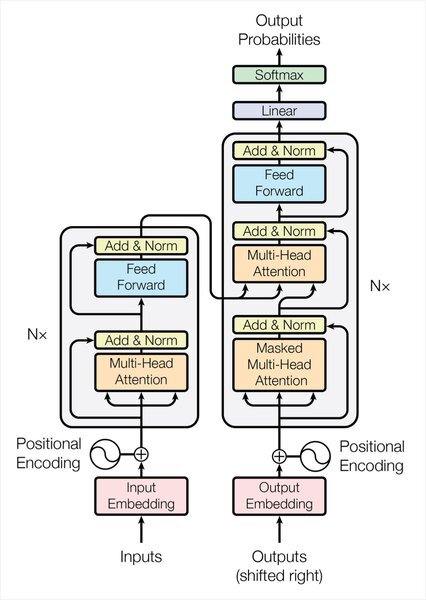
트랜스포머 모델은 Multi-Head Attention이라는 개념을 도입해 폭넓은 문맥을 파악하게 하고, 기존의 RNN 구조를 완전히 탈피하여 연산 속도도 빨라졌다.
'AIFFEL > Going Deeper(NLP)' 카테고리의 다른 글
| [Going Deeper(NLP)] 10. Transformer로 번역기 만들기 (0) | 2022.04.12 |
|---|---|
| [Going Deeper(NLP)] 9. Transformer가 나오기까지 (0) | 2022.04.06 |
| [Going Deeper(NLP)] 6. 임베딩 내 편향성 알아보기 (0) | 2022.03.29 |
| [Going Deeper(NLP)] 5. 워드 임베딩 (0) | 2022.03.28 |
| [Going Deeper(NLP)] 3. 텍스트의 분포로 벡터화 하기 (0) | 2022.03.23 |