728x90
반응형

본 포스팅은 '한빛출판네트워크'의 '혼공SQL' 책을 기반으로 작성한 포스팅입니다.
1. 인덱스의 내부 작동 원리
1.1 균형 트리
- 노드 (node) : 데이터가 저장되는 공간
- 루트 노드 (root node) : 상위노드로 모든 출발의 시작
- 리프 노드 (leaf node) : 마지막 노드
- 중간 노드 (internal node) : 루트노드와 리프 노드 사이의 노드
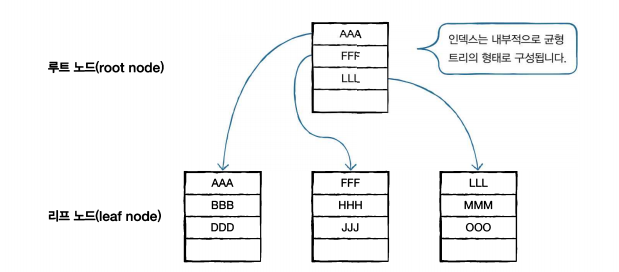
- MySQL에서는 노드를 페이지(page) 라고 부름
- 최소한의 저장 단위
- 16KByte(16384byte) 크기를 가짐
- ex. 데이터를 1건만 입력해도 1개 페이지가 필요함
💡 데이터를 균형 트리로 구성 vs 구성하지 x
- 데이터를 균형 트리로 구성하지 않는다면?
- 전체 테이블 검색(Full Table Scan)을 해야 함

- 균형트리로 구성되어있다면?
- 먼저 루트 페이지(root page)부터 검색

▶ 균형트리가 아닌 구조에서는 3페이지를 읽었지만, 균형트리 구조에서는 2페이지를 읽고 데이터를 검색할 수 있다.
▶ 균형트리로 구성하면 (인덱스가 있으면) 데이터를 빠르게 검색할 수 있음
1.2 균형 트리의 페이지 분할
- 인덱스를 만들면 SELECT의 속도가 향상됨
- 그러나, 데이터 변경 작업(INSERT, UPDATE, DELETE) 시 성능이 나빠짐
- 이유는? 페이지 분할 작업이 발생하기 때문
- III 데이터 1개 추가 (빈 공간O)

▶ 2번째 리프 페이지에 빈 공간이 있어서 페이지 분할 없이 III가 삽입됨
- GGG 데이터 1개 추가 (빈 공간 x → 새로운 리프 페이지 생성)

▶ 2번째 리프 페이지에 빈 공간이 없기에 페이지를 분할하여 새로운 페이지를 생성
- PPP, QQQ 데이터 2개 추가
- 리프 페이지가 추가됨
- 리프 페이지가 증가하면서 루트 페이지가 추가됨
- 루트 페이지가 2개가 되면서 더이상 루트 페이지가 되지 않고 중간 페이지가 됨
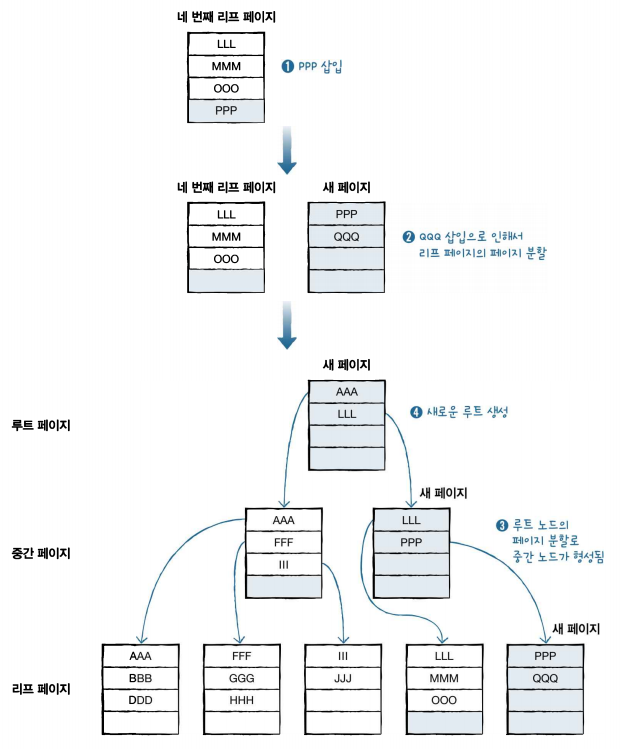
▶ 데이터 1개 입력하기 위해 새로운 페이지 생성 및 페이지 분할이 됨
→ 입력 작업이 오래걸린 것을 확인.
→ 왜 데이터 변경 작업이 느려지는지 확인할 수 있음 (특히, INSERT)
2. 인덱스의 구조
2.1 클러스터형 인덱스 vs 보조 인덱스
📌 클러스터형 인덱스
- 1페이지에 4개의 행이 입력된다고 가정

USE market_db;
CREATE TABLE cluster -- 클러스터형 테이블
( mem_id CHAR(8) ,
mem_name VARCHAR(10)
);
INSERT INTO cluster VALUES('TWC', '트와이스');
INSERT INTO cluster VALUES('BLK', '블랙핑크');
INSERT INTO cluster VALUES('WMN', '여자친구');
INSERT INTO cluster VALUES('OMY', '오마이걸');
INSERT INTO cluster VALUES('GRL', '소녀시대');
INSERT INTO cluster VALUES('ITZ', '잇지');
INSERT INTO cluster VALUES('RED', '레드벨벳');
INSERT INTO cluster VALUES('APN', '에이핑크');
INSERT INTO cluster VALUES('SPC', '우주소녀');
INSERT INTO cluster VALUES('MMU', '마마무');
- 데이터 삽입 후 조회
select * from cluster;

▶ 정렬된 순서가 입력된 순서와 동일함
- mem_id 에 클러스터형 인덱스 구성 (→ PK로 지정)
alter table cluster
add constraint
primary key (mem_id);
▶ mem_id를 기준으로 오름차순 정렬됨

- 각 페이지의 인덱스로 지정된 열의 첫번째 값으로 루트 페이지를 만듦
- 인덱스 페이지의 리프 페이지는 데이터 그 자체
📌 보조 인덱스
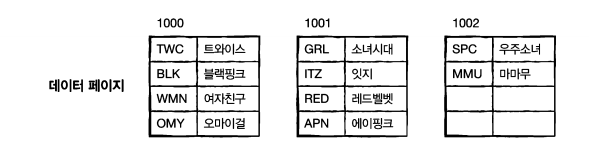
USE market_db;
CREATE TABLE second -- 보조 인덱스 테이블
( mem_id CHAR(8) ,
mem_name VARCHAR(10)
);
INSERT INTO second VALUES('TWC', '트와이스');
INSERT INTO second VALUES('BLK', '블랙핑크');
INSERT INTO second VALUES('WMN', '여자친구');
INSERT INTO second VALUES('OMY', '오마이걸');
INSERT INTO second VALUES('GRL', '소녀시대');
INSERT INTO second VALUES('ITZ', '잇지');
INSERT INTO second VALUES('RED', '레드벨벳');
INSERT INTO second VALUES('APN', '에이핑크');
INSERT INTO second VALUES('SPC', '우주소녀');
INSERT INTO second VALUES('MMU', '마마무');
- 데이터 삽입 후 조회
select * from cluster;

▶ 정렬된 순서가 입력된 순서와 동일함
- mem_id 에 보조 인덱스 구성 (→ UNIQUE로 지정)
ALTER TABLE second
ADD CONSTRAINT
UNIQUE (mem_id);
SELECT * FROM second;
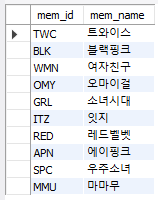
▶ 보조 인덱스가 생성되었음에도 생성되기 전과 동일한 순서로 출력됨

- 리프 페이지에 인덱스로 구성한 열 정렬
- 실제 데이터가 있는 위치 준비
- 데이터 위치 : 페이지 번호+#위치 로 기록되어 있음
- 보조 인덱스를 구성하면 인덱스가 별도의 공간에 만들어짐!
2.2 인덱스에서 데이터 검색 (SELECT문)
❓ SPC 회원의 이름을 검색한다면 몇 개의 페이지를 읽어야 할까?
📌클러스터형 인덱스

- 루트 페이지 읽기
- 루트페이지에 있는 리프페이지로 이동
- 리프 페이지 읽기
▶ 총 2개의 페이지를 읽어서 SCP 회원의 이름을 알아냄
📌 보조 인덱스
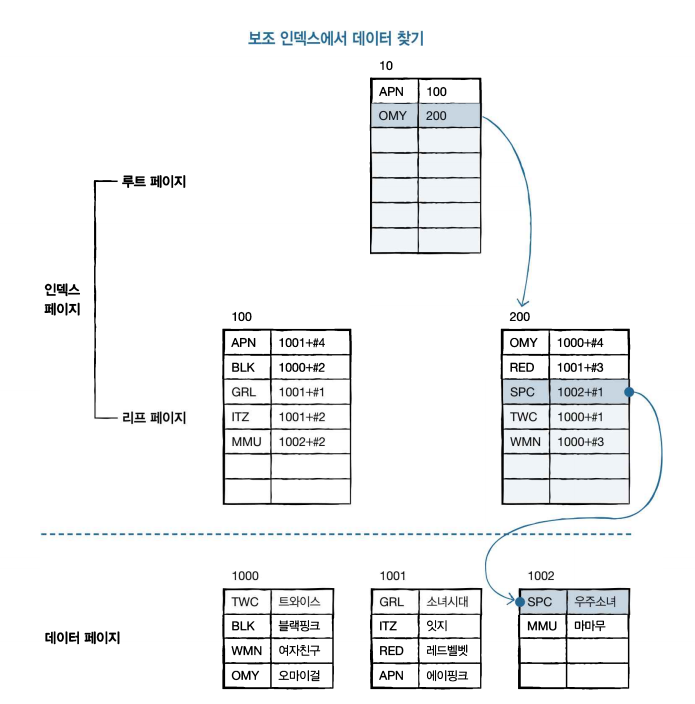
- 인덱스 페이지의 루트 페이지 읽기
- 인덱스 페이지의 리프 페이지 읽기
- 데이터 페이지 읽기
▶ 총 3개의 페이지를 읽어서 SCP 회원의 이름을 알아냄
728x90
반응형
'Data Analysis > 혼공SQL' 카테고리의 다른 글
| [혼공SQL] 7-1 스토어드 프로시저 사용 방법 (0) | 2022.09.01 |
|---|---|
| [혼공SQL] 6-3 인덱스의 실제 사용 (0) | 2022.08.09 |
| [혼공SQL] 6-1 인덱스 개념을 파악하자 (0) | 2022.08.09 |
| [혼공SQL] 5-3 가상의 테이블: 뷰 (0) | 2022.08.03 |
| [혼공SQL] 5-2 제약조건으로 테이블을 견고하게 (0) | 2022.08.03 |