
2주차 교육에 대한 회고 (4L)
벌써 2주차가 끝나간다. 길면 길었고 짧으면 또 짧은 듯하다.이번 주는 동일한 사람들과 자리를 앉아서 5일 내내 같이 점심 먹고 같이 이야기를 했다. 그래서인지 확실히 지난 주보다 더 가까워지고 편해졌다.다음 주는 또 조원들이 바뀌는데, 새로운 사람들과 이야기해볼 수 있는 기회가 생겨서 좋다 :)
이번 주는 파이썬과 SQL 모두 끝이 났다.특히 파이썬에서 시각화에 대해 많이 부족했는데, 이번 교육을 통해서 파이썬으로 시각화를 하는 것에 대해 자세하게 배워서 매우 만족스럽다.
1. 이번주 수업에서 좋았던 점은? (Liked)
2. 이번주에 새롭게 배운 점은? (Learned)
3. 배운 것에 관해서 내가 부족했던 부분은? (Lacked)
4. 앞으로 뭘 더 하면 좋을까? (Longed for)
1. 이번주 수업에서 좋았던 점은? (Liked)
✔ 파트너간 상보적 학습, 멘토링
SQL 강의가 시작되면서 궁금증이 많아졌다. 그런 부분들을 파트너간 상보적 학습 시간, 그리고 더 나아가 쉬는 시간에도 팀원들과 함께 이야기하며 서로 아는 내용들을 말하며 보완해주었다.
이전보다는 팀원들과 좀 더 친해졌고, 팀원들 모두 대화를 잘하는 분들이라서 이 시간을 더욱 알차게 쓸 수 있었다.
멘토링은 첫 주에는 파이썬의 기본적인 문법에 대한 내용이라 많은 도움이 된다고 생각이 들진 않았다.
이후 SQL 강의가 시작되면서 SQL에 대한 요약 설명을 다시 한번 더 해주시고 예제를 같이 푸는 시간을 가졌다. 역시나 내가 직접 쿼리를 작성해보는 것이 많이 도움되는 듯하다.
✔ 다양한 데이터 활용
강의에서 제공된 데이터 이외에 다른 데이터를 활용해서 시각화를 하려고 데이터를 찾아보았다! 도전~!
2. 이번주에 새롭게 배운 점은? (Learned)
✔ 파이썬 시각화
파이썬 기본적인 문법을 공부했었지만, 시각화는 다른 사람이 작성한 코드를 카피하며 했었어서 이 부분이 많이 약했다. 그런데 이번 교육에서 시각화에 대해 엄~청 상세히 알려주셔서 제대로 공부할 수 있었다.
3. 배운 것에 관해서 내가 부족했던 부분은? (Lacked)
✔ 다른 데이터에 적용하지 못함
강의를 듣고 TIL을 쓴다고 하루가 금방 지나갔다. 다른 데이터를 활용해서 시각화하려고 데이터는 찾았지만,,, 그걸 해보지 못했다.
좀 더 부지런해져서 강의 외의 공부도 해야겠다..!
4. 앞으로 뭘 더 하면 좋을까? (Longed for)
✔ 강의 외 공부
이번 주에 부족했던 강의 외 공부를 해보도록 노력해야겠다!ㅠㅠ
집에 오면 피곤해서 풀어지는데, 교육장에서 더 하고 오던지 해야겠다.
지금 하고 있는 통계 스터디도 자꾸 예습을 안하게 되는데, 부지런히 해보자..ㅠㅠ
✔ 오프라인 교육 시작
다음주에 R 강의 3일동안 듣고 오프라인 강의 (Data Driven Design Thinking)이 시작된다.
오프라인 교육이라 더더욱 궁금해진다. 특히 내가 가장 기대했던 커리큘럼 중 하나가 바로 'Data Driven Design Thinking'였다.
어느정도 프로그래밍 언어는 할 수 있지만, 통계 지식과 연계해서 데이터를 분석하는 것이 부족했기에 이 것을 보완할 교육이 필요했다. 교육 잘 들어보자!
2주차 교육 내용 - 23.02.13 ~ 23.02.17
📌 데이터 분석 프로세스

기획 → 데이터 수집 → 데이터 확인 / 전처리 → 데이터 탐색 / 통계 / 시각화 / 모델링 → 인사이트 → 적용
우리는 이 과정 중에서 데이터 수집~시각화까지 기술적인 부분을 배우고 있다.
이 부분 이외의 기획, 인사이트, 적용 단계는 해당 분야의 도메인 지식이 필요하고 개인적인 역량과 관심이 필요하다.
📌 파이썬 시각화
1. displot vs distplot
displot과 distplot 그래프가 있다. 2개의 이름이 거의 동일해서 헷갈릴 수 있지만 다른 그래프이다.
✅ displot
- histplot, kdeplot, ecdplot, rugplot 총 4가지의 plot을 모두 그릴 수 있는 함수
- subplot으로 그릴 수 없는 그래프 figure 레벨에서 그려지는 그래프이기 때문
- subplot에서는 figure라는 하나의 캔버스에 여러 axes가 그려져 보통 axes에 plot이 그려짐

sns.displot(data = titanic, x = 'age', hue = 'alive', col = 'pclass')
✅ distplot
- 히스토그램을 그릴 때 사용하는 그래프
- 러그와 커널 밀도 표시 기능이 있음
- 그러나 최신 버전에서는 사용할 수 없는 그래프로, 대신에 histplot을 사용해야 함
sns.distplot(x, kde=True, rug=True)
plt.title("Iris 데이터 중, 꽃잎의 길이에 대한 Dist Plot")
plt.show()
2. 위도, 경도 데이터를 활용하여 산점도로 지도 그래프 그리기
- 산점도(scatterplot, hexbin)를 그릴 때, 데이터의 x, y 좌표를 설정할 수 있음
- 위도, 경도 데이터가 있으면 이를 x, y 좌표로 설정하여 산점도를 활용해 지도 그래프를 그릴 수 있음
✅ scatterplot 그래프
plt.figure(figsize = (8, 6))
# 시군구명으로 경도, 위도를 평균낸 데이터프레임 생성
df_store_seoul_location = df_store_seoul[['시군구명', '경도', '위도']].groupby('시군구명').mean()
# 커피전문점/카페/다방인 데이터만 추출한 데이터프레임 생성
df_store_seoul_class3 = df_store_seoul[df_store_seoul['상권업종소분류명'] == '커피전문점/카페/다방']
sns.scatterplot(data = df_store_seoul_class3
, x = '경도', y = '위도'
, hue = '시군구명' # 데이터를 그룹핑할 컬럼
, marker = '.', alpha = 0.1) # 마커를 .으로 하여 작게 표현, alpha로 투명도 조절
plt.legend(ncol = 2, loc = (1.01, 0))
# 시군구명의 평균 경도, 위도를 활용하여 지도에 시군구명을 표현
for i in range(len(df_store_seoul_location)):
x = df_store_seoul_location.iloc[i, 0]
y = df_store_seoul_location.iloc[i, 1]
text = df_store_seoul_location.index[i]
plt.text(x, y, text, ha = 'center')
plt.title('커피전문점/카페/다방', size = 20)
plt.show()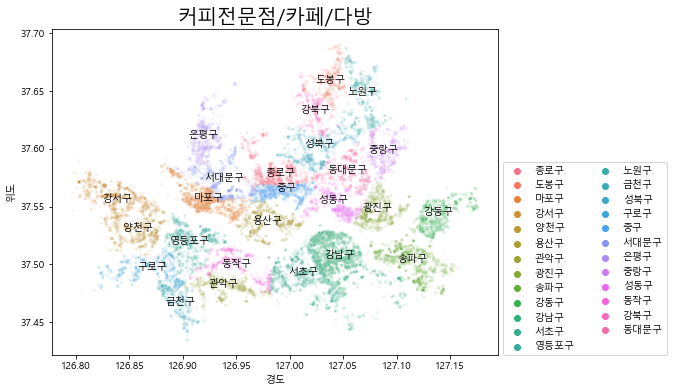
✅ hexbin 그래프
plt.figure(figsize = (8, 6))
# 시군구명으로 경도, 위도를 평균낸 데이터프레임 생성
df_store_seoul_location = df_store_seoul[['시군구명', '경도', '위도']].groupby('시군구명').mean()
# 커피전문점/카페/다방인 데이터만 추출한 데이터프레임 생성
df_store_seoul_class3 = df_store_seoul[df_store_seoul['상권업종소분류명'] == '커피전문점/카페/다방']
plt.hexbin(df_store_seoul_class3['경도'], df_store_seoul_class3['위도']
, cmap = 'Blues'
, gridsize = 30) # x축 기준 그리드 한 칸의 크기
plt.colorbar()
# 시군구명의 평균 경도, 위도를 활용하여 지도에 시군구명을 표현
for i in range(len(df_store_seoul_location)):
x = df_store_seoul_location.iloc[i, 0]
y = df_store_seoul_location.iloc[i, 1]
text = df_store_seoul_location.index[i]
plt.text(x, y, text, ha = 'center')
plt.title('커피전문점/카페/다방', size = 20)
plt.show()
📌 SQL
1. ERD (Entity Relationship Diagram)
테이블 간의 관계를 설명해주는 다이어그램으로, ERD로 DB의 구조를 한 번에 파악할 수 있다.
MySQL WorkBench에서 가지고 있는 데이터프레임의 ERD를 확인할 수 있는 기능이 있다.
PK, FK도 표시되어 있으며, 어떻게 데이터끼리 관계를 맺고 있는지 확인할 수 있다.
데이터에 테이블이 많을 경우, 한 눈에 파악할 수 있어서 편하다.
Database > Reverse Engineer


2. IF ~ / CASE WHEN ~ / IFNULL ~
✅ IF
- 하나의 조건을 제시할 때 사용함
- IF (조건, 참일 때 값, 거짓일 때 값)
SELECT IF (100 > 300, '크다', '작다');
✅ CASE WHEN
- 여러 개의 조건을 제시할 때 사용함
- CASE WHEN 조건1 THEN 반환값1
WHEN 조건2 THEN 반환값2
ELSE 충족되는 조건이 없을 때 반환값
END
SELECT custid
, SUM(saleprice) AS '총구매액'
, (CASE WHEN (SUM(saleprice) >= 60000) THEN '최우수고객'
WHEN (SUM(saleprice) >= 45000) THEN '우수고객'
WHEN (SUM(saleprice) >= 30000 ) THEN '일반고객'
ELSE '유령고객'
END) AS '고객등급'
FROM Orders
GROUP BY custid;
✅ IFNULL
- 데이터가 null이라는 조건에 사용함
- IFNULL(데이터, 데이터가 null일 때 출력 값)
[예제 1] 고객별 총 주문횟수, 총구매액, 평균구매액, 최소/최대구매액 구하기
# 구매하지 않은 고객 포함하기
# 구매하지 않은 고객은 집계 결과 0으로 표현하기
# 총 구매액 순으로 순위 매기기 (RANK)
1) CASE WHEN 활용
SELECT C.USERNAME AS '이름'
, COUNT(O.ORDERID) AS '총 주문횟수'
, (CASE WHEN SUM(O.SALEPRICE) IS NULL THEN 0 ELSE SUM(O.SALEPRICE) END) AS '총 구매액'
, (CASE WHEN AVG(O.SALEPRICE) IS NULL THEN 0 ELSE AVG(O.SALEPRICE) END) AS '평균 구매액'
, (CASE WHEN MIN(O.SALEPRICE) IS NULL THEN 0 ELSE MIN(O.SALEPRICE) END) AS '최소 구매액'
, (CASE WHEN MAX(O.SALEPRICE) IS NULL THEN 0 ELSE MAX(O.SALEPRICE) END) AS '최대 구매액'
, RANK() OVER (ORDER BY SUM(O.SALEPRICE) DESC) AS RANKING
FROM CUSTOMER AS C
LEFT JOIN ORDERS AS O
ON C.CUSTID = O.CUSTID
GROUP BY 1;
2) IFNULL 활용
SELECT C.USERNAME AS '이름'
, COUNT(O.ORDERID) AS '총 주문횟수'
, IFNULL(SUM(O.SALEPRICE), 0) AS '총 구매액'
, IFNULL(AVG(O.SALEPRICE), 0) AS '평균 구매액'
, IFNULL(MIN(O.SALEPRICE), 0) AS '최소 구매액'
, IFNULL(MAX(O.SALEPRICE), 0) AS '최대 구매액'
, RANK() OVER (ORDER BY SUM(O.SALEPRICE) DESC) AS '순위'
FROM CUSTOMER AS C
LEFT JOIN ORDERS AS O
ON C.CUSTID = O.CUSTID
GROUP BY 1;
3. 윈도우 함수 RANK (순위함수)
- RANK () OVER(PARTITION BY 컬럼명 ORDER BY 컬럼명)
✅ 순위함수
| 함수 | 설명 | 예시 |
| RANK(속성) | 공동 순위만큼 건너뜀 | 1, 2, 2, 4, 5 |
| DENSE_RANK(속성) | 공동 순위를 뛰어넘지 않음 | 1, 2, 2, 3, 4 |
| ROW_NUMBER(속성) | 공동 순위를 무시함 | 1, 2, 3, 4, 5 |
[예제 2] 고객별 saleprice 랭킹
SELECT c.username
, b.bookname
, o.saleprice
, RANK() OVER (PARTITION BY C.USERNAME ORDER BY O.SALEPRICE) AS '순위'
FROM orders o, customer c, book b
WHERE o.custid=c.custid AND o.bookid=b.bookid;
4. GROUP BY ~ WITH ROLLUP
- 항목별 합계에 전체 합계(소계)가 같이 출력됨
[예제 3] 지역 - 도서 별 판매 수량 / 지역 별 판매수량 소계
- IFNULL을 사용하면 '소계' 컬럼의 데이터를 NULL 값이 아닌 '-----소계-----'로 출력 가능
⭐ 도서명을 IFNULL로 구했기 때문에, GROUP BY엔 2, 또는 '도서명'으로 입력하면 '-----소계-----'가 출력이 되지 않음
→ 컬럼명(B.bookname)으로 GROUP BY에 입력해야 함!
SELECT SUBSTRING_INDEX(address, ' ', 1) AS '지역'
, IFNULL(B.bookname, '-----소계-----') AS '도서명'
, COUNT(*) AS '판매수량'
, SUM(O.saleprice) AS '판매금액'
FROM CUSTOMER C, ORDERS O, BOOK B
WHERE C.custid = O.custid
AND O.bookid = B.bookid
GROUP BY 1, B.bookname WITH ROLLUP;
* 유데미 큐레이션 바로가기 : https://bit.ly/3HRWeVL
* STARTERS 취업 부트캠프 공식 블로그 : https://blog.naver.com/udemy-wjtb
본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터분석/시각화 학습 일지 리뷰로 작성되었습니다.
'웅진X유데미 STARTERS > 주간 학습일지' 카테고리의 다른 글
| [유데미 스타터스 취업 부트캠프 4기] 데이터분석/시각화(태블로) - 6주차 학습 일지 (0) | 2023.03.19 |
|---|---|
| [유데미 스타터스 취업 부트캠프 4기] 데이터분석/시각화(태블로) - 5주차 학습 일지 (1) | 2023.03.12 |
| [유데미 스타터스 취업 부트캠프 4기] 데이터분석/시각화(태블로) - 4주차 학습 일지 (1) | 2023.03.05 |
| [유데미 스타터스 취업 부트캠프 4기] 데이터분석/시각화(태블로) - 3주차 학습 일지 (0) | 2023.02.26 |
| [유데미 스타터스 취업 부트캠프 4기] 데이터분석/시각화(태블로) - 1주차 학습 일지 (0) | 2023.02.12 |