
1. 활용 데이터
Advanced Tableau Course: Download Practice Datasets | Page | Art of Visualization
You can download here all the Advanced Tableau course Practice Datasets files.
www.artofvisualization.com
위의 사이트에 있는 데이터를 활용하여 태블로 강의가 진행된다.
2. 그룹, 집합
2.1 과제 개요
📢 벤처 캐피탈 펀드의 이사회는 현재 잠재적으로 흥미로운 1000개의 스타트업을 검토하고 그들이 투자할 스타트업을 결정하고 있다.
이 펀드에 대한 투자를 선택하는 기준은 높은 수익, 낮은 비용, 최고 성장이며, 모두 2015년 기준이다. (최고 성장이 전체에서 최고 성장을 의미한다고 가정)
당신의 임무는 이사회가 최고의 투자 기회를 나타내는 기업을 식별하는데 도움을 주는 것이다.
2.2 데이터
P11-1000-Startups.xlsx
→ Financials 시트- Overview 시트 (inner join)
2.3 폴더 만들기
[+] 태블로에 있는 폴더로 작업하기
측정값과 차원이 매우 많은 경우가 있으므로 작업공간을 정리할 수 있는 방법을 확인해보자.
→ 데이터 우클릭 > 폴더별 그룹화 클릭
1) 중복된 필드 제거
→ 동일한 컬럼들 (ID, Name) 제거
2) Finance(재무)를 위한 폴더 생성
→ 우클릭 > 폴더 만들기

2.4 그룹 작업하기
그룹화의 방법은 총 2가지가 있다.
① 그룹화하길 원하는 데이터 선택 > 우클릭 > 클립 아이콘 클릭
② 필드 우클릭 > 만들기 > 그룹 클릭
💡 보통 평균 데이터를 그룹화하게 되면 그 평균의 평균을 계산할 것이다.
그러나 태블로는 데이터 2개의 평균의 평균을 계산하는 것이 아니라 데이터 2개의 데이터 전체의 평균을 계산한다.
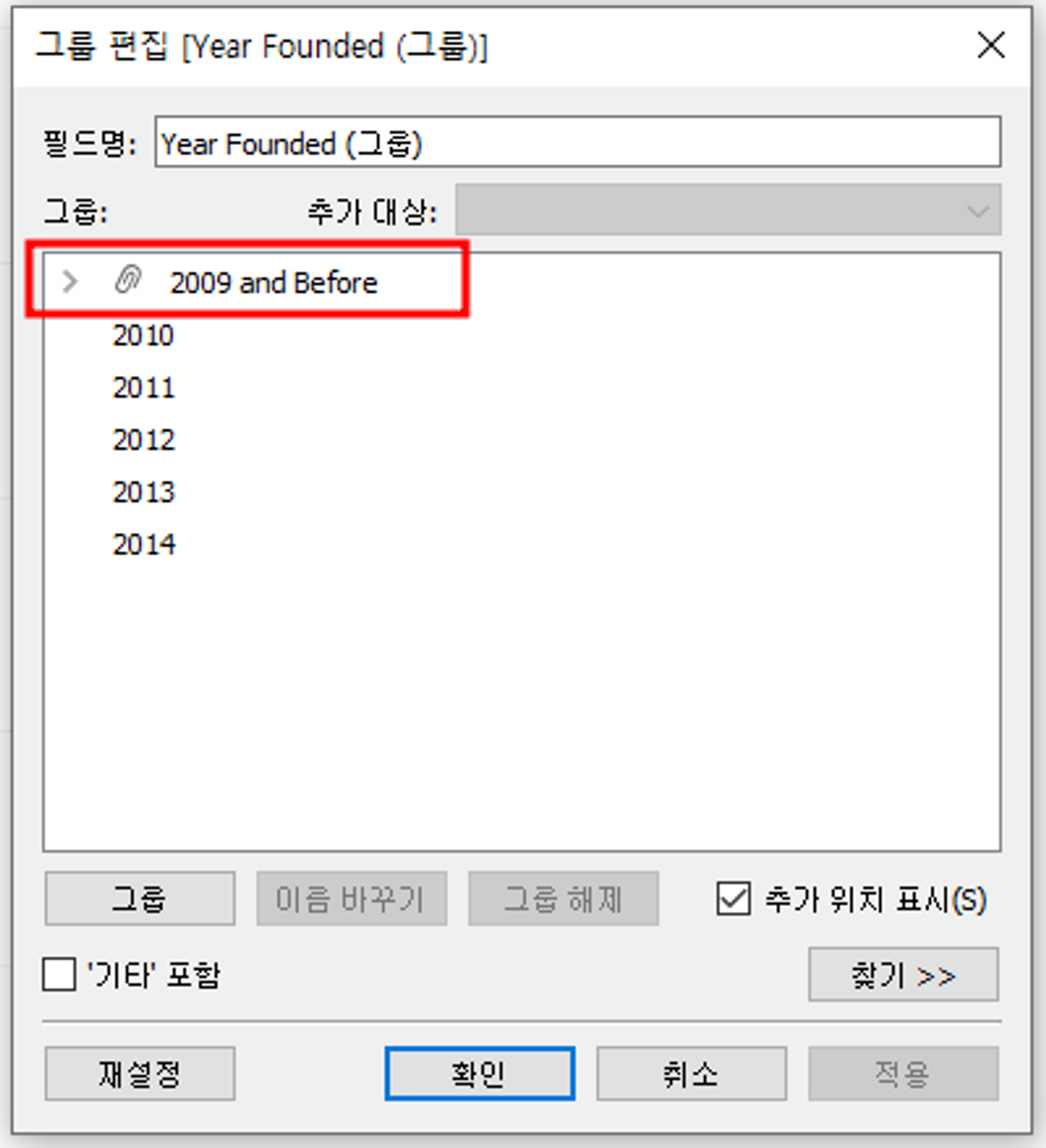
1) 특정 연도 그룹화
1999년 ~ 2008년까지 그룹화하여 그래프로 나타내고자 한다.

생성된 그룹 필드를 클릭하여 편집하여 원하는 그래프를 그려보자.
→ 그룹 이름 변경하기
→ 그룹으로 묶긴 데이터 이외의 데이터도 기타 그룹으로 묶여있는데, 해당 그룹 해제
→ [+] 추가로 해당 창에서 데이터를 그룹으로 옮길 수 있음

2) 특정 산업 그룹화

Telecommunications , IT Services ,Computer Hardware , Software
4개의 산업을 Information Technology 로 그룹화하고자 한다.
위와 같이 동일하게 그룹화를 해주면 다음과 같이 하나의 그룹이 생기고 그래프에 나타난다.

2.5 집합 생성하기
📌 집합을 생성하는 방법
① 정적 집합
② 동적 집합
▶ 정적 집합은 하드코딩이 되며 데이터가 변경되거나 분석의 변화에 따른 상태를 조정할 수 없는 반면, 동적 집합은 이러한 단점이 없다.
1) 정적 집합
✅ Industries Sets (특정 산업 집합)
- Information Technology 그룹으로 묶인 산업들 4개를 그룹으로 묶지 않고 그래프로 확인하고 싶음
- 그래프에서 모든 산업을 보고 싶지만 이 산업 4개만 색을 칠하고 싶음
→ 원하는 데이터 선택 > 고리 아이콘 클릭 > 집합 만들기 > 집합을 색상 마크에 드래그

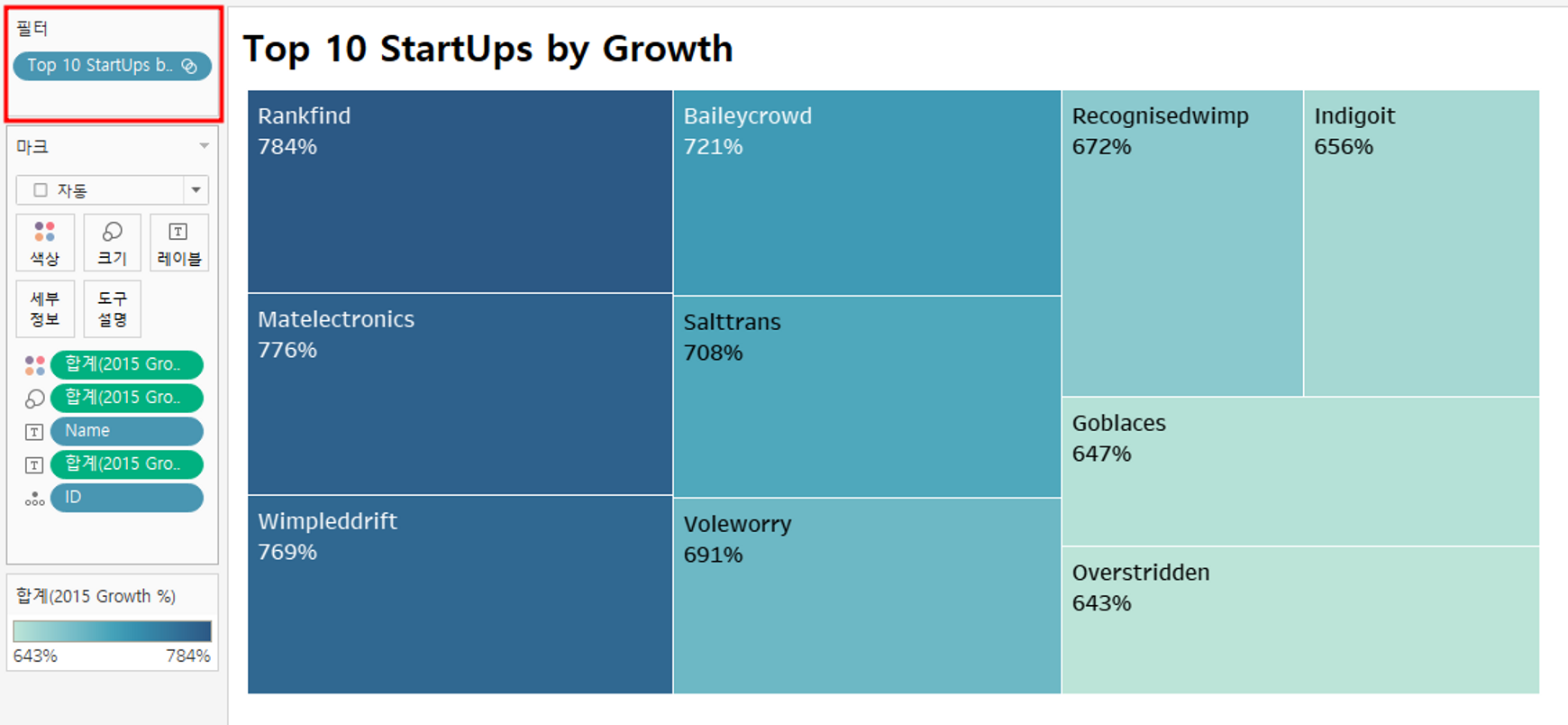
✅ 성장율 높은 10개의 스타트업 집합
🔎 한 번에 백분율 지정 : 필드 클릭 > 기본 속성 > 숫자 형식
성장율을 기준으로 가장 높은 10개의 스타트업을 집합으로 묶어준다.
해당 스타트업들만 트리맵으로 나타내보자.
→ 필터에 묶어준 집합을 추가하면 된다.
2) 동적 집합
집합으로 묶었지만 집합에 포함할 데이터를 변경할 수 있다.
→ 필드 클릭 > 만들기 > 집합 > 일반 - 모두 사용 > 상위 - 필드 기준

✅ 수익과 지출 확인 + 9,000,000 달러 이상의 수익 확인
→ 필드 클릭 > 만들기 > 집합 > 일반 - 모두 사용 > 조건 - 필드 기준

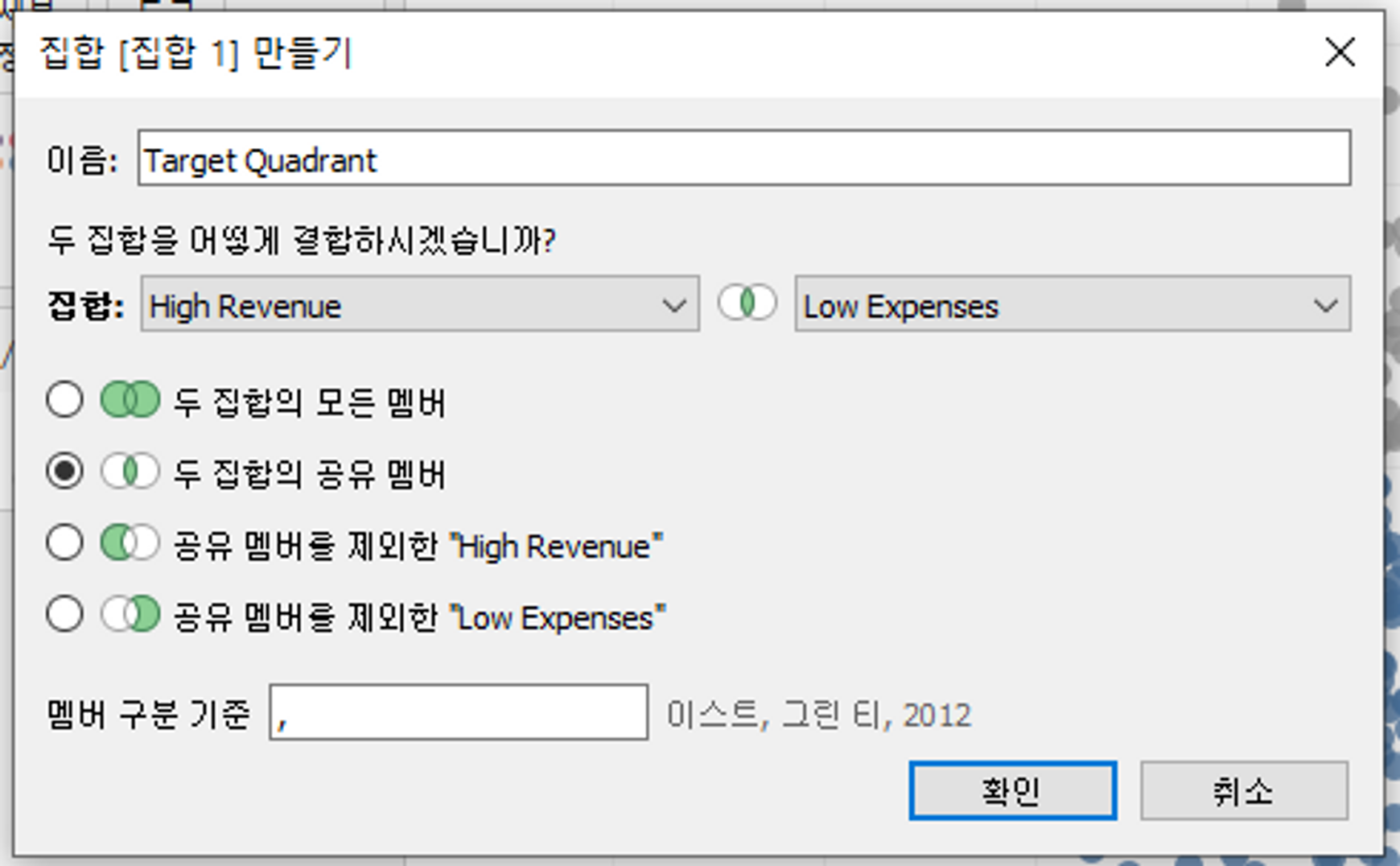
3) 집합 결합하기
2개의 동적 집합을 결합하면 하나의 동적 집합을 만들 수 있다.
→ 집합 필드 클릭 > 결합된 집합 만들기
🔎 축 뒤집기 : 축 우클릭 > 축 편집 > 눈금 반전
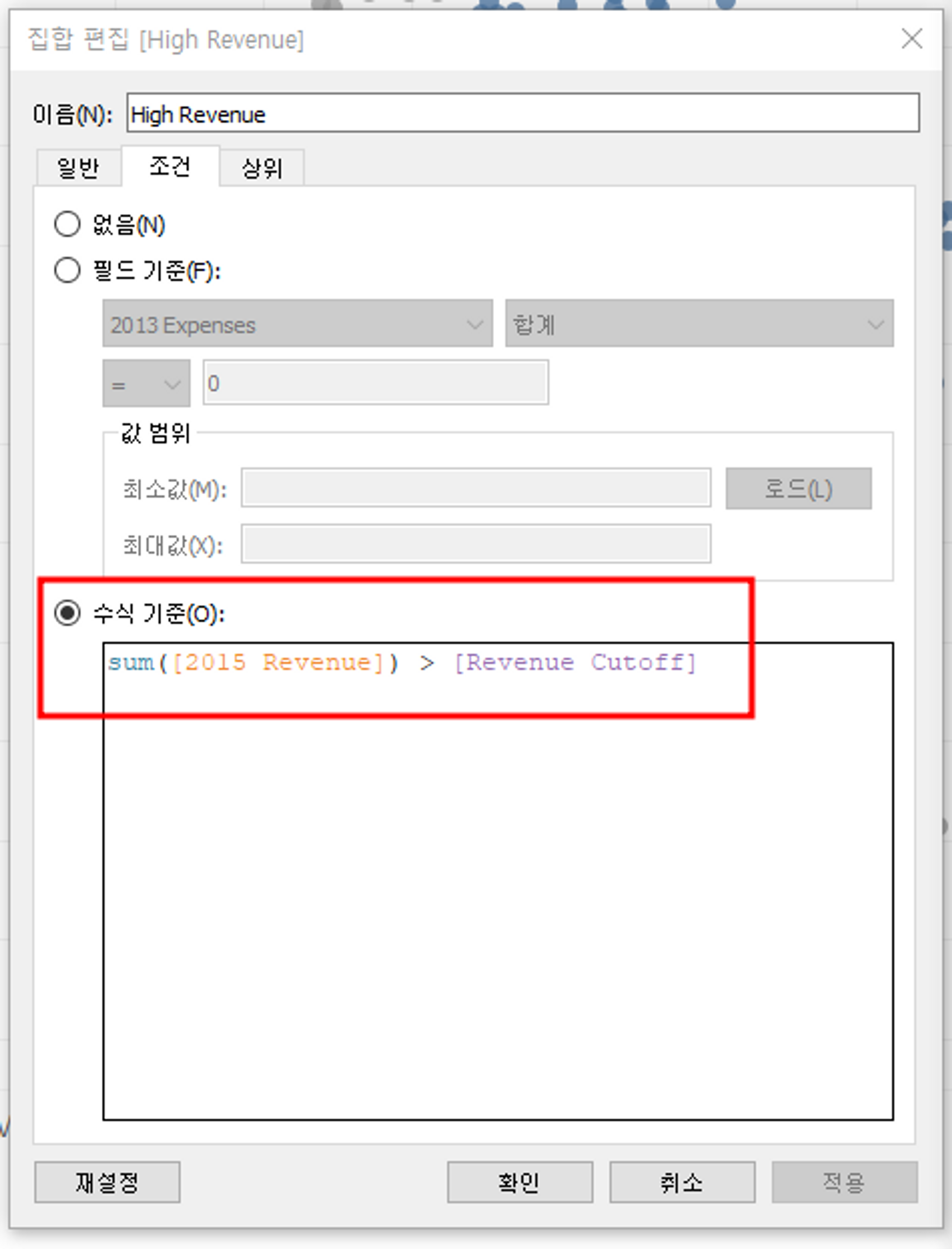
4) 매개변수로 집합 제어하기
매개변수를 생성해서 집합에 포함될 데이터들을 설정할 수 있다.
① 매개변수 만들기
② 만든 매개변수를 기존 집합과 연결하기
내가 원하는 조건에 맞춰서 집합을 설정할 수 있다.
(여기서는 일정 수익 이상, 일정 비용 이하의 범위를 가진 매개변수를 집합과 연결하고, 그 매개변수보다 크거나 작은 조건을 집합에 설정하여 그래프로 보여줌)
→ 집합 편집 > 조건 - 수식 기준
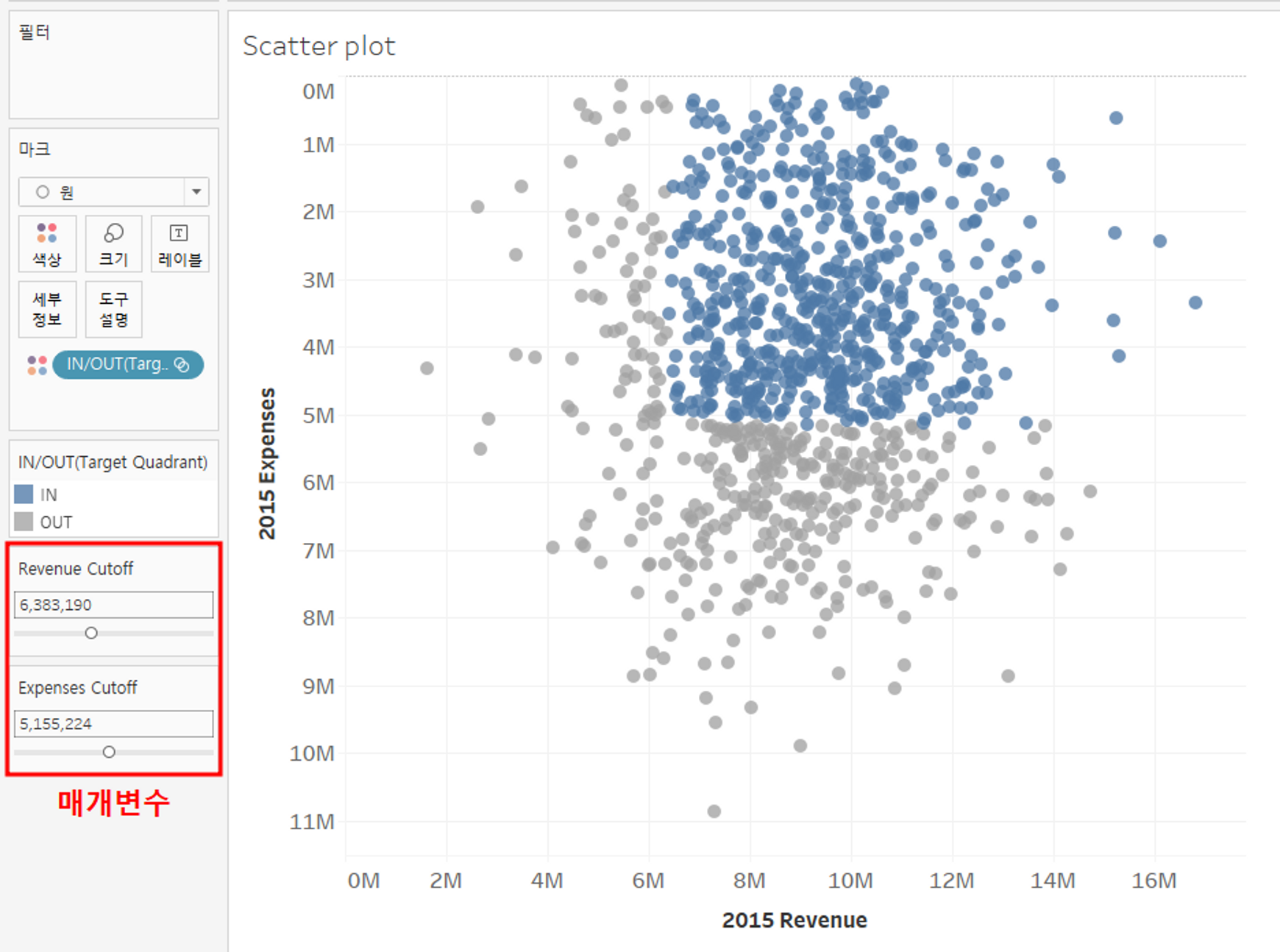
2.6 대시보드 만들기
대시보드 내에 있는 그래프들이 다 관련이 있는 그래프이기 때문에, 여러 그래프 중 동일한 데이터는 동일한 색으로 설정하는 등 연관성이 있도록 표시를 하는 것이 다른 사람들이 보고서를 보는 것이 편하다.
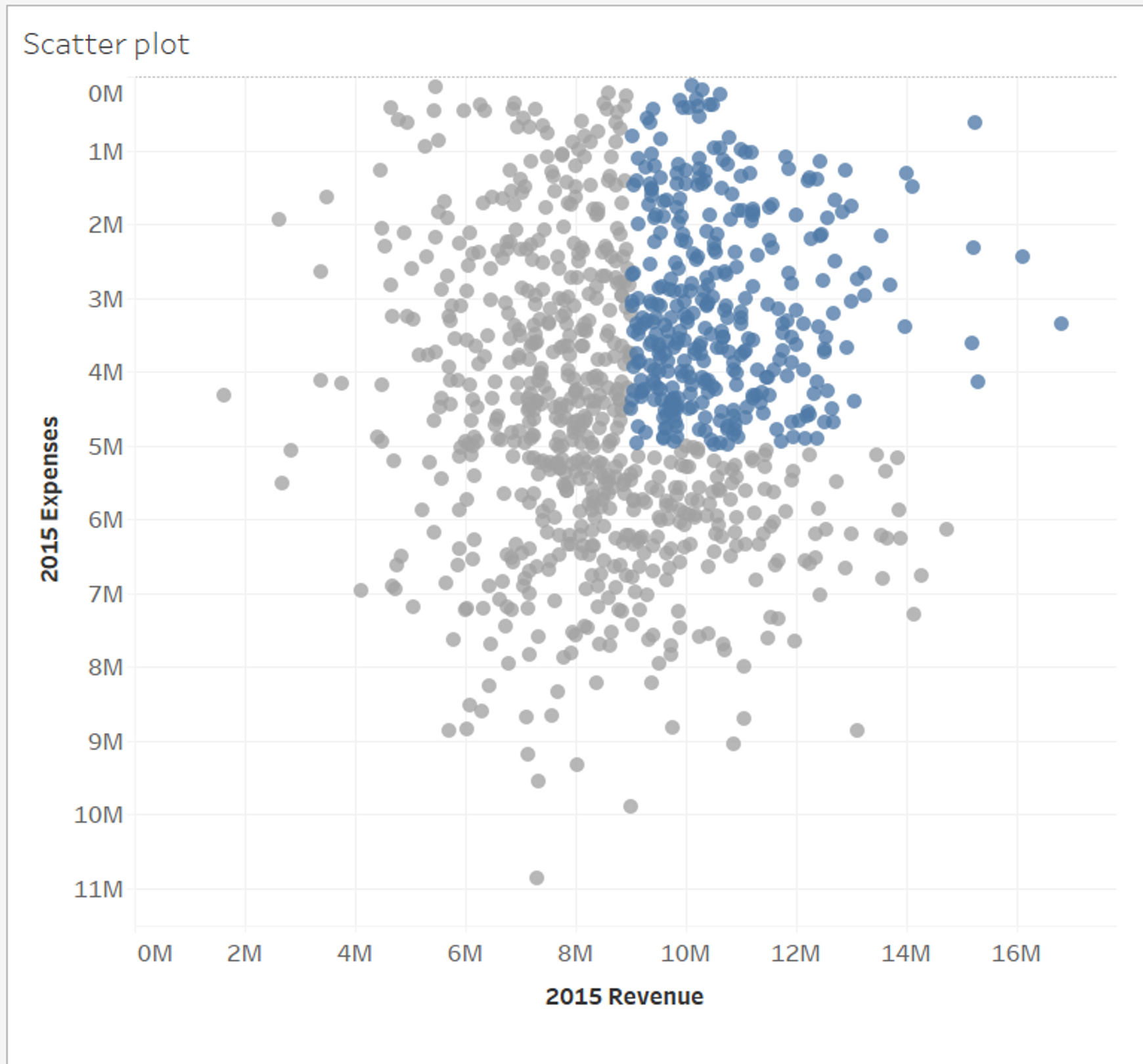
📌 scatter plot
- 파란색 원형 : 9,000,000 달러 이상의 수익 + 5,000,000 달러 미만의 비용 스타트업
- 빨간 다이아몬드 : 그 중에서 성장률이 높은 상위 n개의 스타트업 (Growth Leaders 매개변수로 갯수 수정 가능)
📌 Growth
- Growth Leaders 매개변수로 원하는 갯수 출력 (scatter plot의 빨간 다이아몬드와 연관)

데이터를 한 눈에 볼 수 있도록 대시보드를 깔끔하게 수정해보자.
- 참조선 : Revenue 축 우클릭 > 참조선 추가
- 축 연장선 : 그래프 시트 우클릭 > 축 연장선 > 축 연장선 표시
- 툴팁 : ① 워크시트 > 도구설명 편집 ② 수정할 시트로 이동 > 도구 설명 클릭
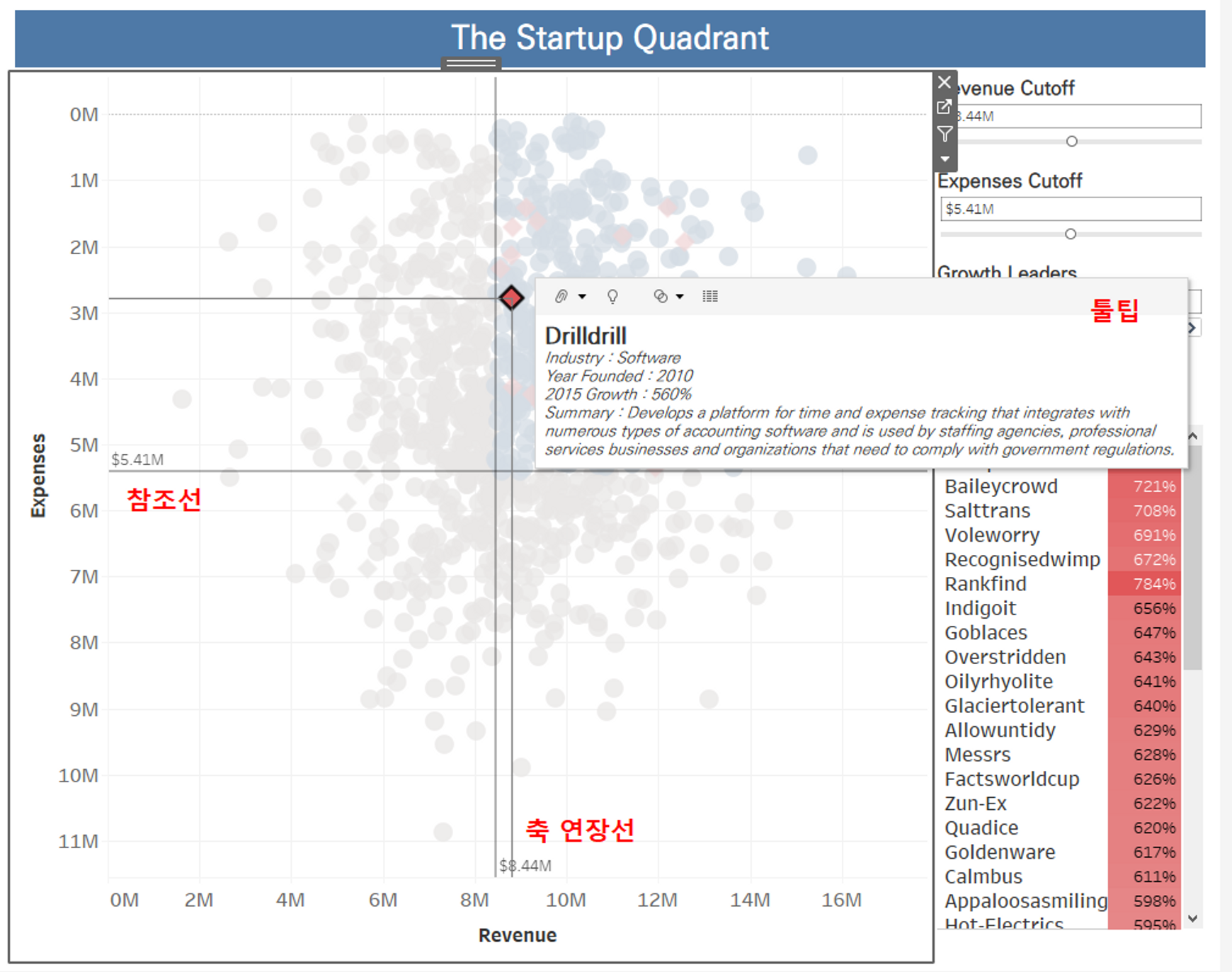
👇 최종 시각화 결과물 👇

3. 테이블 고급 계산
3.1 과제 개요
📢 석탄 채굴 과제 (석탄 터미널에서 작동하는 기계)
석탄 터미널에 어떤 석탄 회수기 기계가 유지보수가 필요하며, 다음 달을 평가해야 한다.
기계는 1년 365일 24시간으로 작동을 하며, 1분의 가동 중지 시간은 수백만 달러의 수익 손실과 동일하다. 따라서 기계의 유지보수가 필요한 시점을 파악하는 것이 중요하다.
회수기형 기계는 전월에 최소 8시간동안 유휴 생산 능력이 10%를 초과했다면 유지보수가 필요하다.
✔ 유휴 생산 용량 : 실제 톤수에서 규격 용량을 빼고 규격 용량으로 나눈 것 (유휴 생산 용량은 클수록 좋지 않은 기준)

5개의 기계 중 어떤 기계가 유휴 생산 용량이 10% 초과했는지 확인해보고 경영진을 위해 권장 사항이 포함된 보고서를 작성해라.
3.2 데이터
기존에 있는 첫번째 시트에 Left Join을 하게 되면 첫번째 시트에는 없는 시간대가 있을 수 있기 때문에 시간대만 있는 시트(Timeline)를 새롭게 만들어준 후, 그 시트를 기준으로 모든 데이터를 Left Join하는 방향으로 진행


3.3 계산된 필드 vs 테이블 계산
📌 계산된 필드 : 집계 전에 수행되며 데이터 집합 수준에서 수행된다. 계산된 필드는 데이터 집합을 분석하는 열로 포함하려는 새 측정값, 또는 새 차원으로 만들고자 할 때 사용한다.
📌 테이블 계산 : 집계 후에 수행되며 태블로 자체에서 계산이 된다.
✅ 합계와 누계 그래프
→ 합계 필드 우클릭 > 퀵 테이블 계산 > 누계

✅ 합계와 차이 그래프
→ 합계 필드 우클릭 > 퀵 테이블 계산 > 차이
→ 합계 필드 우클릭 > 기준 > 다음

3.4 고급 테이블 계산
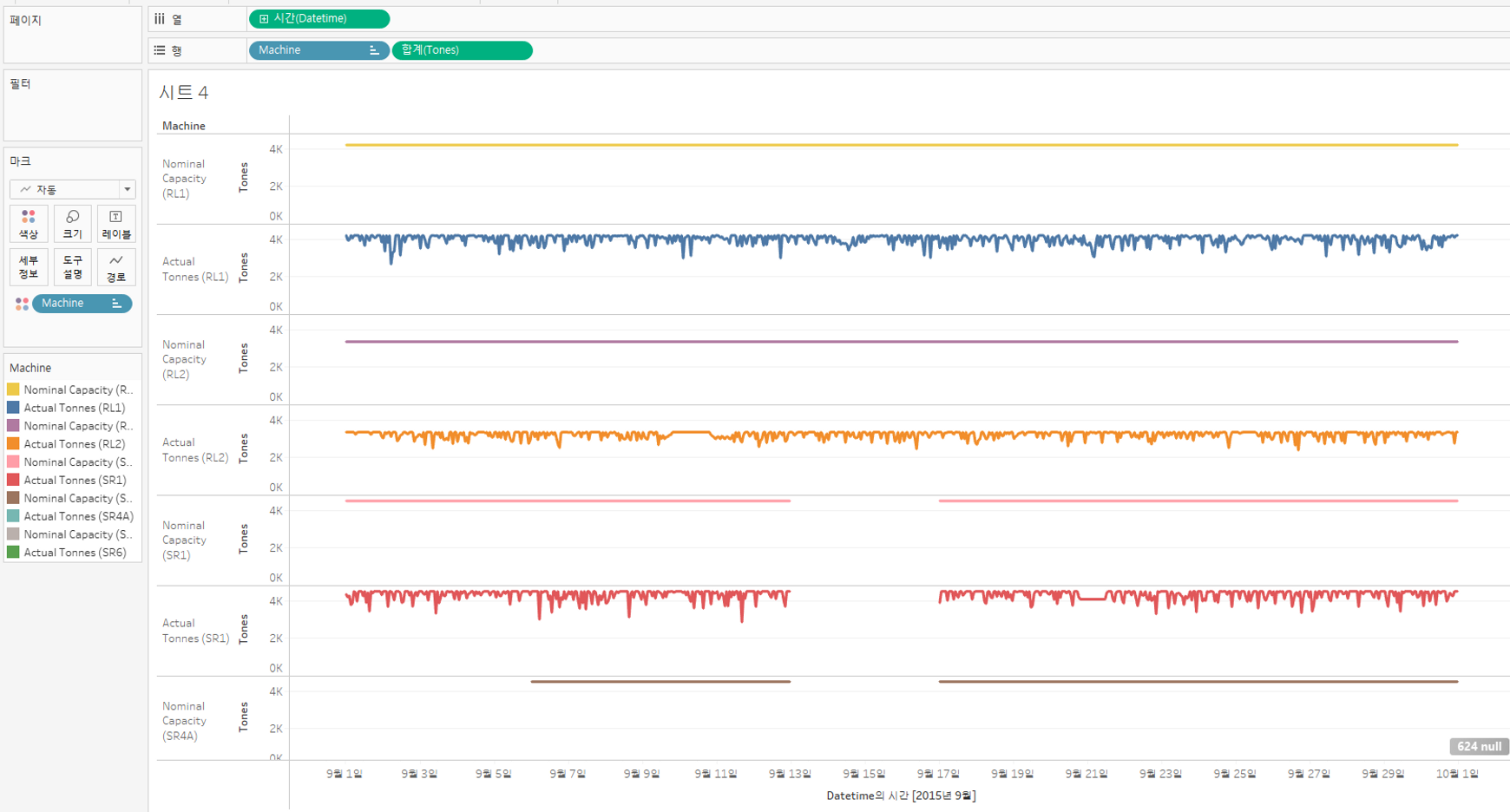
규격 용량과 실제 용량의 차이를 나타내는 그래프를 만들어보자.
① 아래와 같이 x, y축 기준으로 그래프 생성
- x축 : 시간 (Datetime)
- y축 : machine 별 규격 용량 & 실제용량
② 규격 용량과 실제 용량의 차이 확인
→ 합계(Tones) 우클릭 > 퀵 테이블 계산 > 차이
→ 합계(Tones) 우클릭 > 다음을 사용해서 계산 > 테이블 (아래로)
→ 규격 용량 그래프는 숨기기 (실제 용량 그래프만 보이게 하기)
테이블 위아래로 차이를 계산하여 그래프가 그려진 것인지 확인해보기 위해서는 숫자 테이블을 생성하여 확인할 수 있다.
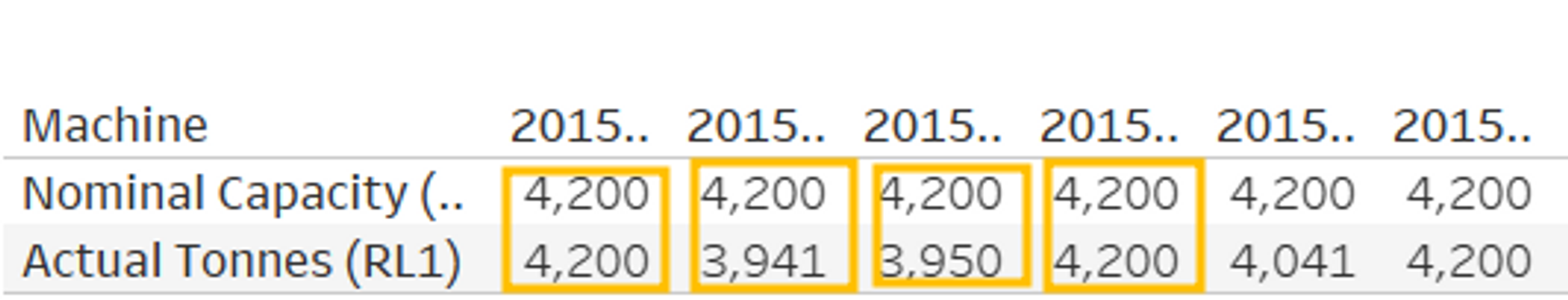

3.5 퀵 테이블 계산 저장하기
유휴 생산 용량을 톤에서 백분율로 변경해보자.
① 톤에서 백분율로 변경하기 (유휴 생산 용량)
→ 합계(Tones) 우클릭 > 퀵 테이블 계산 > 비율차이
→ 합계(Tones) 우클릭 > 다음을 사용해서 계산 > 테이블 (아래로)
▶ (실제 용량 - 규격 용량) / 규격 용량 = 유휴 생산 용량(%)

💡 현재 음수로 표현이 되었는데, 유휴 생산 용량은 주어진 시간동안 기계가 얼마나 저조한 성능을 발휘했는지 보여주는 지표이기 때문에 음수가 의미가 있다.
② 10% 참조선 추가하기
→ 축 우클릭 > 참조선 추가

③ 축 뒤집기
그래프가 아래로 되어있으면 보기에 불편하기 때문에 축을 뒤집는다.
그러나 축을 뒤집어도 그대로 음수로 표현되기 때문에 양수로 변경해보자.
데이터도 양수, 축도 양수로 변경하려면 그래프에서 값을 -1로 곱하면 된다.
→ 합계(Tones) 필드를 측정값으로 드래그 > 이름 수정 (Idle Capacity Percent)
→ Idle Capacity Percent 시트 우클릭 > 만들기 > 계산된 필드 > -1 곱하기
→ 참조선도 -10%에서 10%로 변경
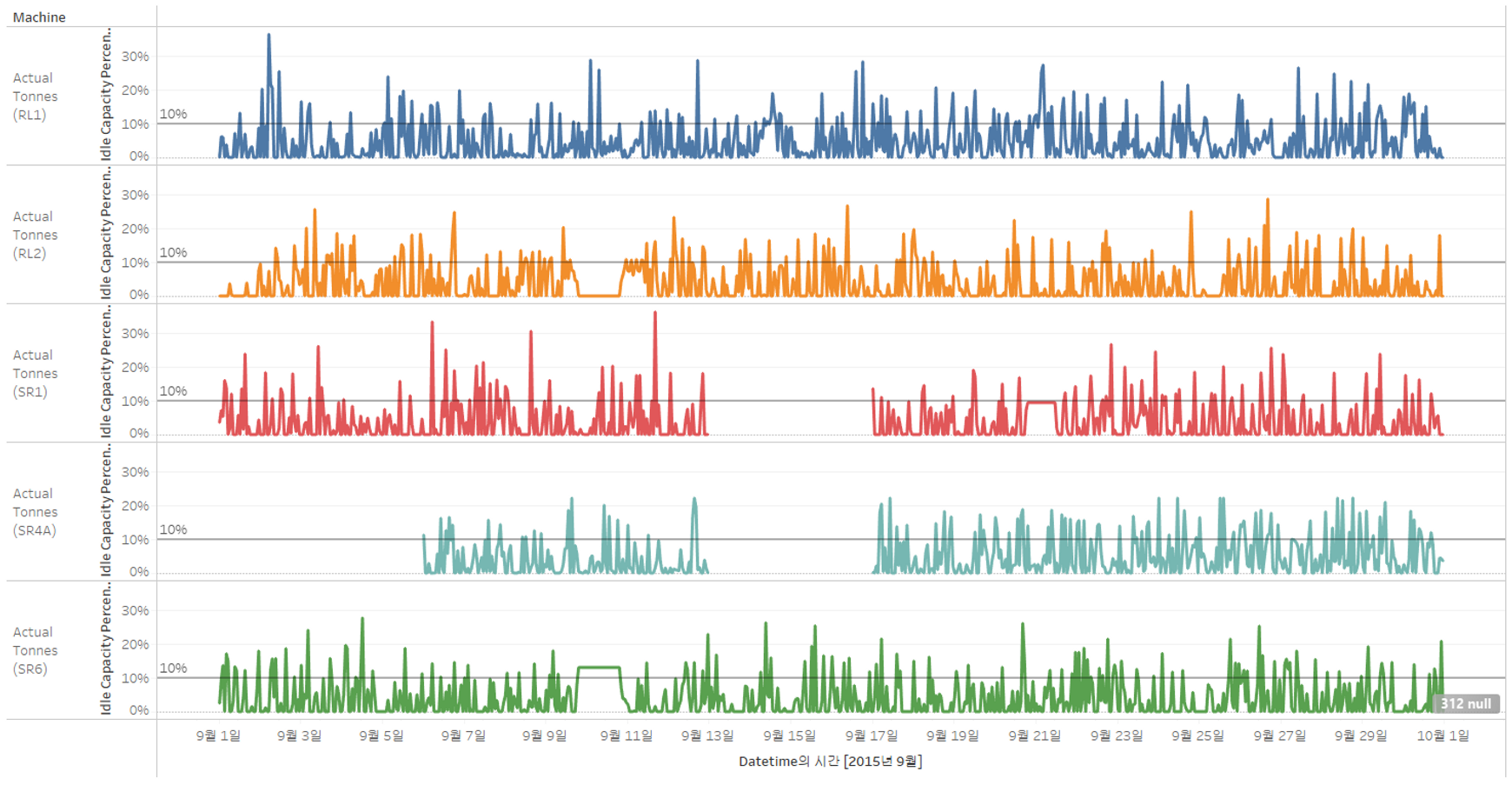
🔎 그래프 사이에 공백이 있는 이유?
RL1, RL2는 회수기로, 항상 석탄을 회수하고 배로 보낸다.
반면 SR1, SR4A,SR6는 스태커 회수기로, 스태커는 특정 기간에 석탄을 쌓고 회수하기 떄문에 그래프 사이에 공백이 있다.
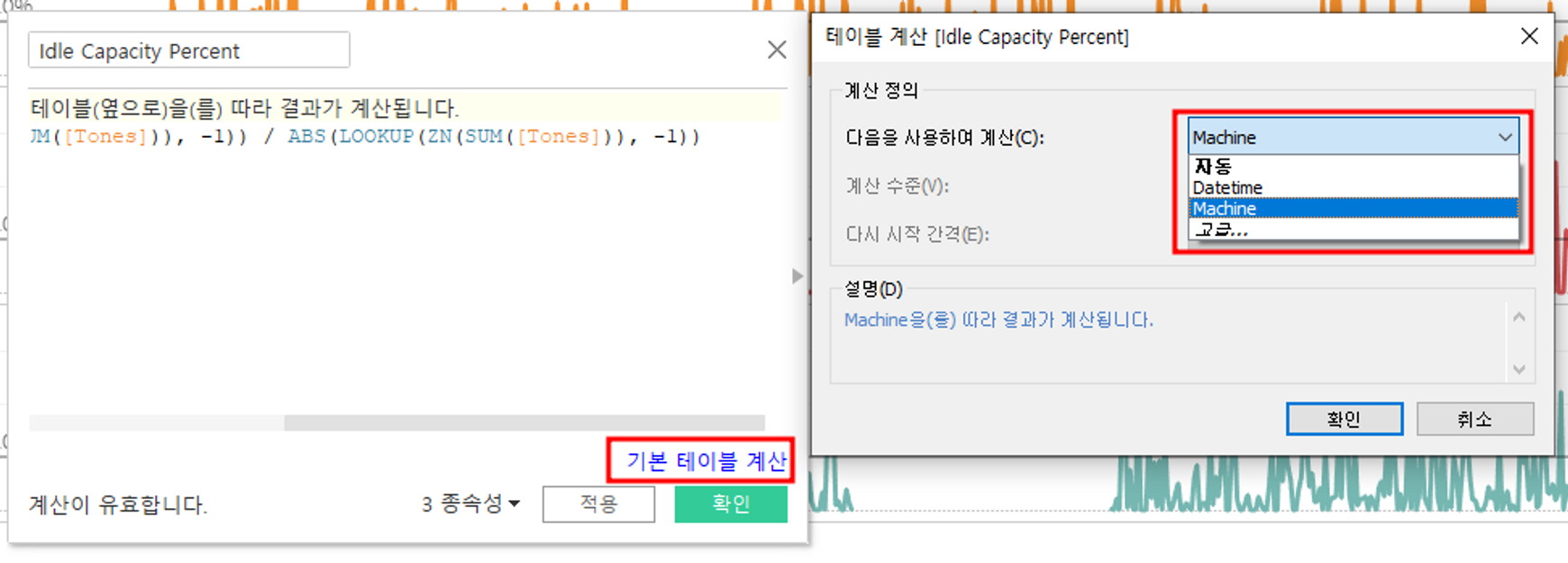
3.6 계산 방향 지정하기
계산 방법은 변경했지만 저장된 테이블 계산에서는 변경되지 않는다.
시트에서 계산방법을 변경한다고 실제로 저장된 테이블 계산을 변경하는 것은 아니다.
저장된 테이블 계산을 업데이트하면 계산 방향이 수정이 된다.
이렇게 명시적 지정을 사용하였을 때 생길 수 있는 잠재적 오류를 방지할 수 있기 때문에 되도록 사용하면 좋다.
→ 기본 테이블 계산 클릭 > 다음을 이용하여 계산 - Machine
→ 명시적 지정된 필드를 드래그하여 업데이트하기!
3.7 나만의 테이블 계산 작성하기
계산된 필드를 생성할 때 사용하는 함수들에 대해 간단히 알아보자.
✅ FIRST : 현재 롤에서 파티션의 첫번째 행까지 행수를 반환함

✅ Running_avg : 위치의 첫번째 행에서 현재 행까지 주어진 표현식의 평균을 첫 행으로 반환
(실행은 항상 첫번째 행에서 시작하는 것으로 되어있음)

✅ Window_avg : 현재 행보다 왼쪽, 오른쪽에 있는 n개의 막대들의 평균 (이동평균)
WINDOW_AVG(sum([Tones]), -7, 0)
window는 작업하려는 행의 일부와 간격을 의미한다.
현재 막대에서 n개의 막대들의 이동 평균을 나타내줌 (빨간색 박스처리)
아래의 그래프에서는 총 8개의 막대들의 평균이 나타나있다.

3.8 이동 평균 테이블 계산
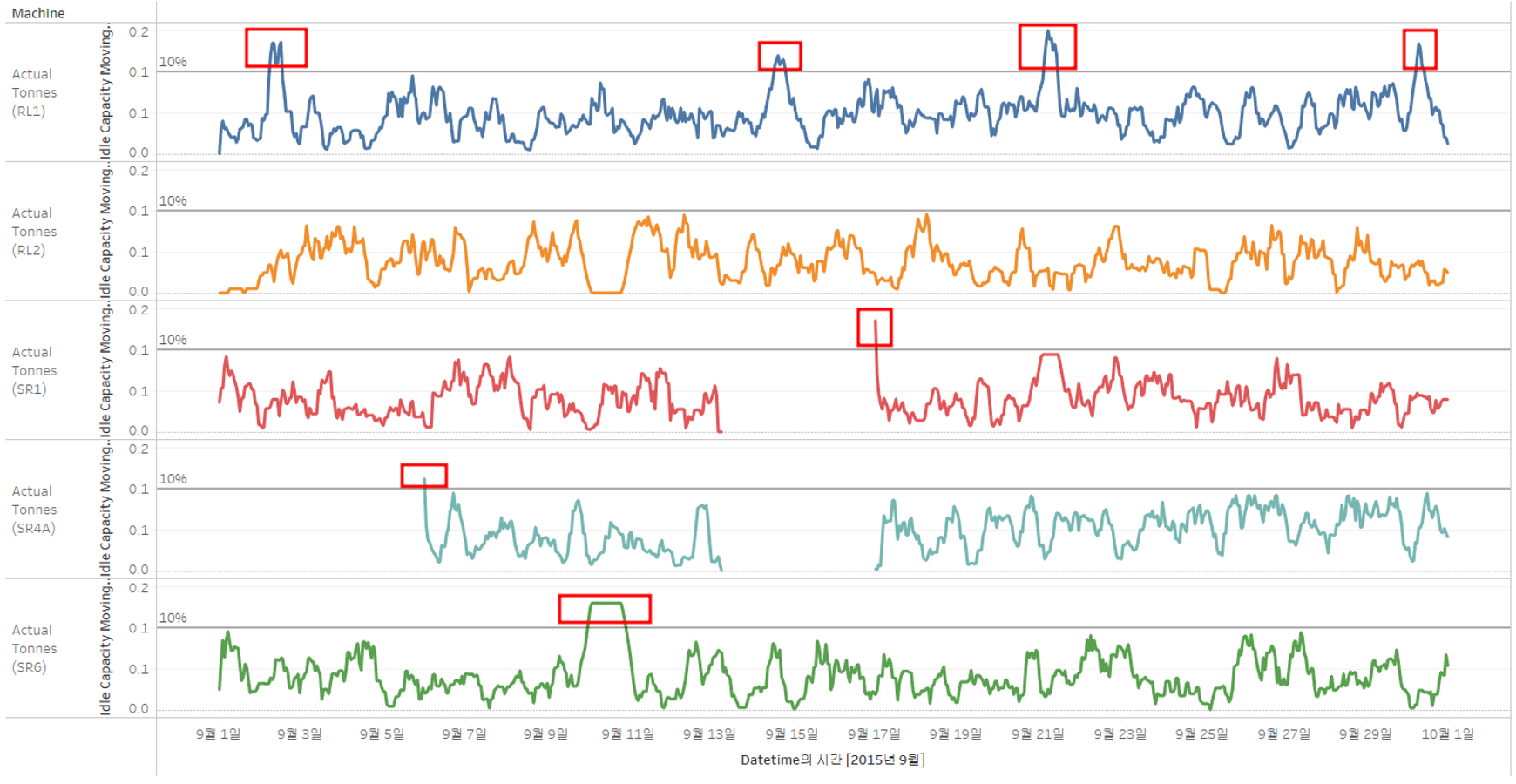
유지보수가 필요한 기계를 결정하는데에 도움이 되는 8시간 이동 평균을 계산해보자.

매시간마다의 평균이 아닌 8시간마다의 평균을 그래프에서 확인할 수 있다.
3.9 테이블 계산을 위한 품질 보증
SR1, SR4A 장비의 경우, 시작 지점에 10%가 넘어가는 것을 확인할 수 있다.
이는 이 기간에 대한 데이터가 부족하여 생기는 급증일 수도 있다.
따라서 이것을 없앨 수 있도록 차트를 수정하거나 유지관리가 필요한 기계인지 확인하기 위해 추가적으로 알아봐야한다.
→ 데이터에서 확인해본 결과, 데이터의 공백으로 인해 오류가 발생하였으며 이를 해결하고자 한다.
✅ 데이터가 충분하지 않으면 이동 평균을 계산하지 않는다는 조건 추가하기
# 막대(데이터)의 갯수가 8이면 막대의 평균을 반환하고 그렇지 않으면 0을 반환한다.
IF (WINDOW_COUNT([Idle Capacity Percent Pos], -7, 0) = 8)
THEN WINDOW_AVG([Idle Capacity Percent Pos], -7, 0)
ELSE NULL
END
그래프가 변경된 것을 확인할 수 있다.
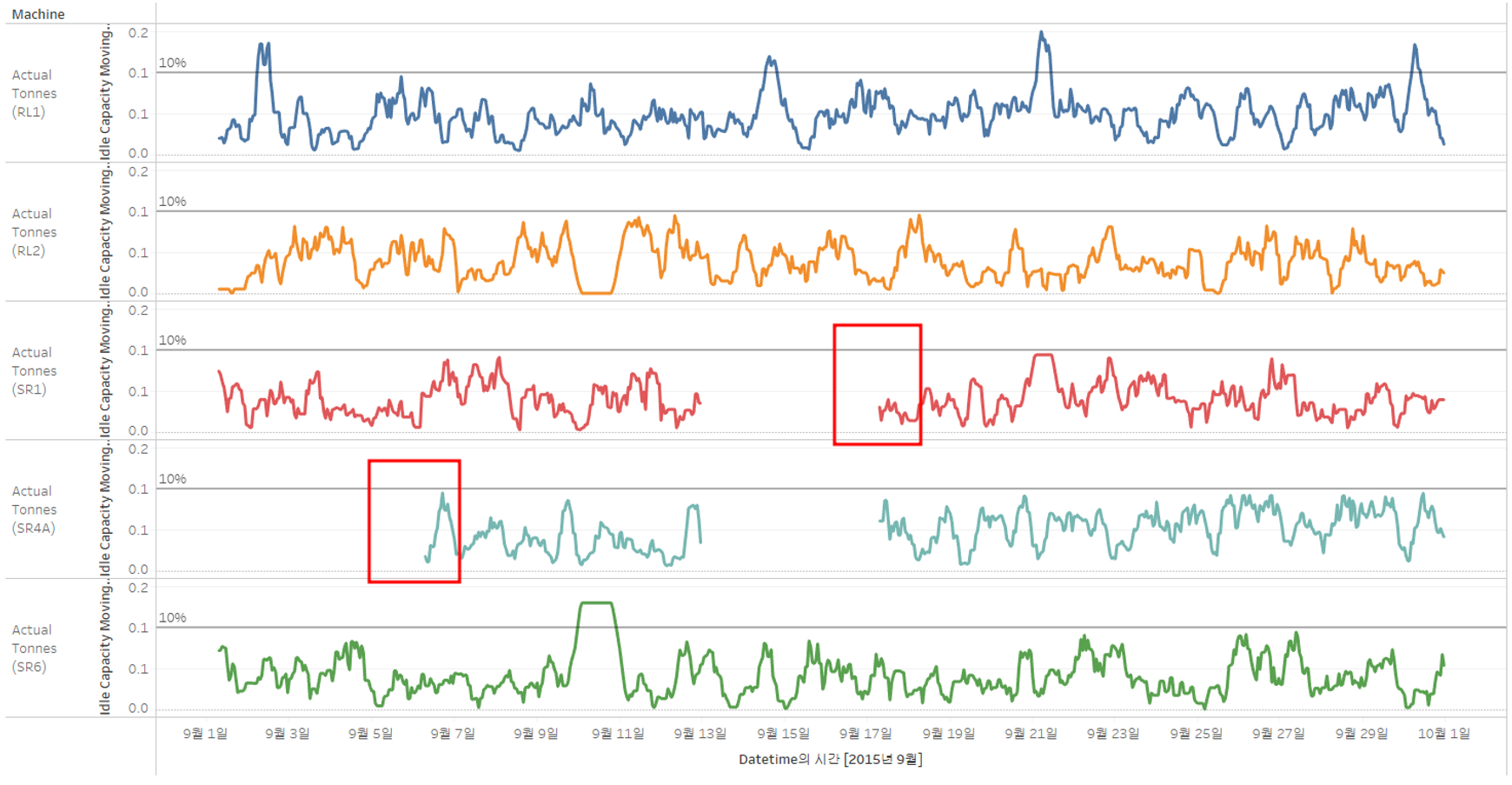
3.10 Power-Insights의 추세선
❓ SR6의 그래프 중 10%가 넘은 구간은 왜 직선으로 되어있을까?
❓ 동일한 구간에 RL2의 그래프도 직선으로 되어있는데 어떠한 관련이 있을까?

→ SR6와 RL2는 같은 라인에 있기 때문에 특정 상황이 발생하였을 경우, 모두 문제가 생긴다. 기간을 보니 갑자기 발생한 일은 아니고 계획된 일임을 알 수 있다. SR6으로 더 높은 용량을 달성하기 위해 RL2를 대신하여 계획한 것이다.
▶ 두 기계 사이의 일종의 교차 상관관계가 있다.

✅ 추세선
태블로가 자동으로 데이터에 선형 회귀선을 맞춰 전체 트렌드가 어디로 가는지 알려준다.
→ 우클릭 > 추세선 > 추세선 표시
p값을 찾아 0.05와 비교를 할 수 있다.
p값이 0.05보다 작으면 추세선의 결과가 통계적으로 유의미하다
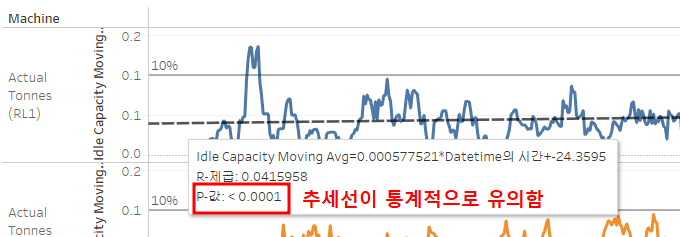

✔ SR4A 장비
추세선을 보면 10%에 매우 빠르게 접근하고 있다.
평균 유휴 생산 용량은 10시간에 0.12%정도 증가한다. (빨간 박스 참고)
그렇기 때문에 10월에는 해당 장비를 유지보수 해야 할 것이다.

3.11 스토리라인 만들기
워크시트를 스토리라인으로 드래그해서 가져오게 된다면 수정할 사항들이 있다.
그러나 스토리라인은 대시보드와 다르게 수정이 불가하기 때문에 바로 드래그해서 가져오면 안 된다.
→ 대시보드에 워크시트를 추가한 후 대스보드를 스토리에 가져오기

4. 고급 데이터 준비, 분석
4.1 과제 정의
📢 의류 소매 업계에서 운영되는 호주 소매 체인점에서 일하고 있다.
이 회사는 호주의 뉴사우스웨일즈에서만 운영되고 있다. 하지만 이사회는 퀸즈랜드, 빅토리아, 서호주 3개의 주 중 하나로 확장을 고려하고 있다.
이 3개의 주 각각 해당 산업의 비즈니스 환경을 평가하고 그 결과를 이사회에 직접 제출해라.
4.2 박스플롯
📌 데이터 셋 : P11-Competitor-Research.csv

① 열 : State / 행 : Net Profit Margin / 색상 : State
② 분석 > 측정값 집계 해제 (→ 막대그래프가 개별 데이터로 분리됨)
③ 좌측에 있는 분석 탭 > 박스 플롯 드래그
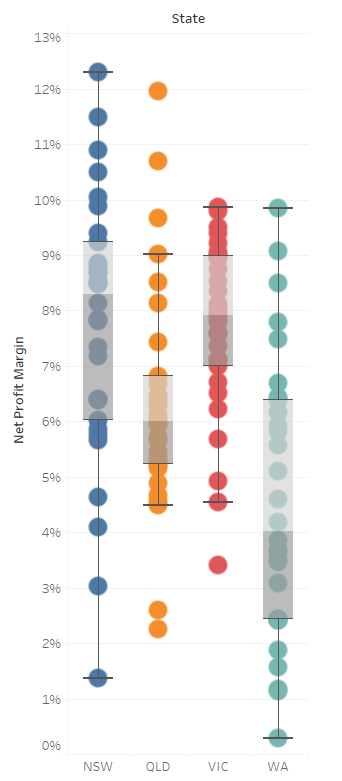
- 뉴사우스웨일즈, 퀸즈랜드, 빅토리아 : 실적이 저조한 회사가 있음
- 퀀즈랜드 : 실적을 초과한 회사가 있음
- 서호주 : 박스 부분이 상당히 크기 때문에 순이익률 측면에서 다소 불확실함
- 빅토리아 : 중앙 값이 다른 주보다 높음, 박스 부분이 높이 있음, 데이터가 모여있음 → 순이익률 측면에서 불확실성이 적음
▶ 빅토리아주가 사업 확장과 비즈니스 환경 측면에서 나은 것을 확인할 수 있음
4.3 대용량 데이터 소스 작업하기
호주의 여러 주에 있는 다양한 산업에 대한 데이터셋을 살펴보자.
📌 데이터 셋 : P11-8501011-Retail-Turnover-State-by-Industry-Subgroup.xlsx
① 원하지 않는 열 제거
- 로우 데이터를 확인하여 필요하지 않은 행과 열을 제거한다.
- 피벗을 하게 될 경우, null값만 있는 열이 있으면 되지 않는다. 그렇기 때문에 null값만 있는 열을 모두 직접 제거해준다.
② 데이터 소스 필터 적용
- 데이터의 양이 많기 때문에 태블로에서 사용하면 시각화를 하는데 오래 걸리기도 한다. 그래서 필터를 걸어 데이터의 양을 줄인다.
③ 피벗 및 분할
- 피벗해서 태블로 프로그램이 읽을 수 있도록 설정한다.
- 컬럼을 분할하여 주 이름과 산업 이름을 새로운 컬럼으로 추가한다.

4.4 소매업 분석
① 열 : 월(Date) / 행 : State, Industry, 합계(Turnover $M)
② 모든 그래프의 축을 각 그래프에 맞춰서 설정 : Turnover $M 축 우클릭 > 각 행 또는 열에 독립적인 축 범위
③ 데이터 소스 필터 적용한 것 해제 : 데이터 > 데이터 원본 필터 편집 > 제거
→ 데이터셋 : 1982년과 2015년 사이의 전체 기간
✅ 옷, 액세서리, 전자제품, 음식 소매업
- 12월에 수익이 가장 높음 : 크리스마스, 새해, 박싱데이 등
- 2월에 수익이 가장 낮음 : 12월에 신용카드 사용 후 돈을 지불해야 하여 소비가 줄어드는 달
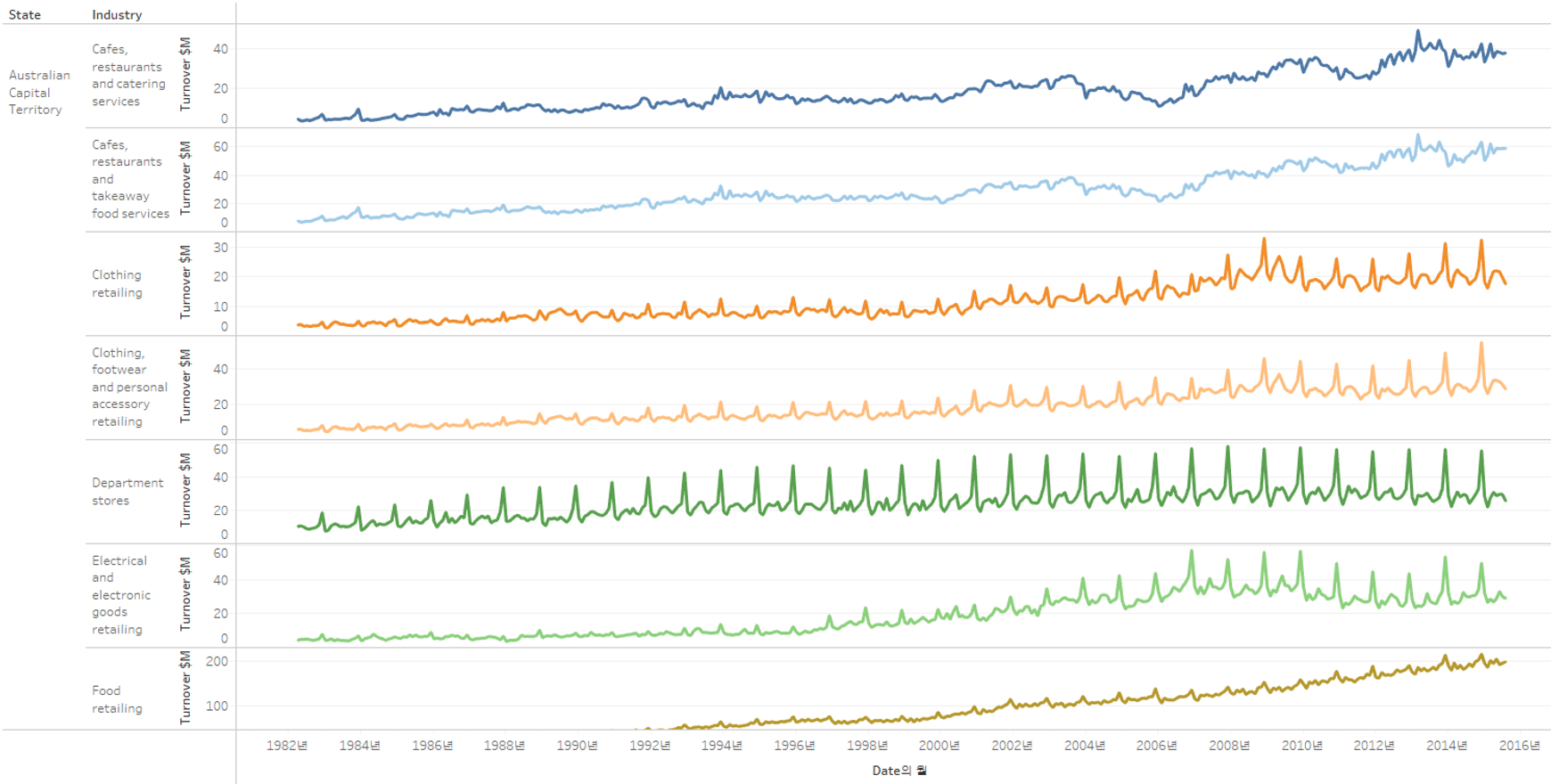
✅ 신문, 책 소매업
90년대 초반까지는 성장하였으나 컴퓨터, 스마트폰이 보급되면서 2010년 이후 급락하고 있음

4.5 데이터 소스 필터
시각화를 생성하는 행 수를 제한한 다음 해상도가 준비되면 필터를 제거하여 대용량 데이터 작업을 쉽게 할 수 있다.
✔ 데이터 소스 필터의 주 목적 : 분석에 사용하지 않을 카테고리나 행을 완전히 제거
🔎 시트에 있는 필터를 활용하여 필터링할 수 있지만, 다음과 같이 데이터 자체에 필터링하고자 하는 이유는 필터가 데이터 소스 수준에 있게 하기 위함이다.
→ Industry 필드에 다른 산업 데이터는 나타나지 않음
① 의류 소매업 산업 데이터만 필터링
→ 데이터 > 데이터 원본 필터 편집 > Industry - Clothing retailing 선택
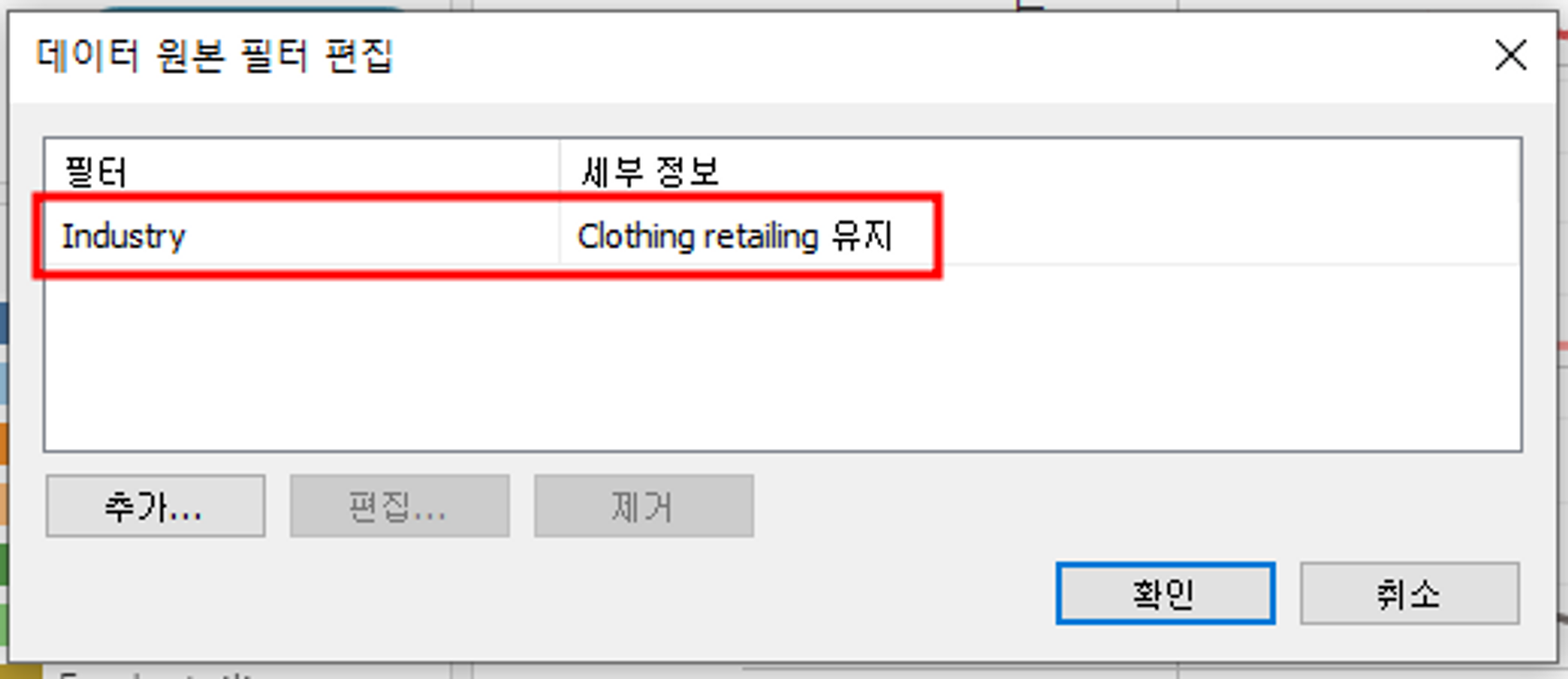
② 날짜 데이터 필터링
15년 전의 상황과 현 상황이 매우 달라졌기 때문에 지난 15년 간의 데이터로 확인해보자.
→ 데이터 > 데이터 원본 필터 편집 > Date - 2000/01/01 ~

4.6 추세선
특정 주의 데이터를 보고자 필터링하였다. (데이터 소스 필터말고 시트에서 필터 진행함)
해당 데이터의 추세선을 그려보았다.
→ 분석 > 추세선 드래그

4.7 소매업 별 수익 + 인구 데이터
1) 데이터 준비하기
📌 데이터 셋 : `P11-310104-Australian-Demographic-Statistics.xlsx`
① 피벗 및 분할
- 피벗해서 태블로 프로그램이 읽을 수 있도록 설정
- 컬럼을 분할하여 주 이름과 산업 이름을 새로운 컬럼으로 추가
② 데이터 소스 필터
- 성별이 여러 카테고리로 있기 때문에 필터링 진행 (`Persons` 데이터만 남김)
2) 시계열 데이터 혼합
2개의 데이터를 혼합하는 방법을 살펴보자.
① 우선, 두 데이터 집합 사이에 존재하는 관계를 확인하고 데이터끼리 관계를 설정한다.
→ 데이터 > 혼합 관계 편집
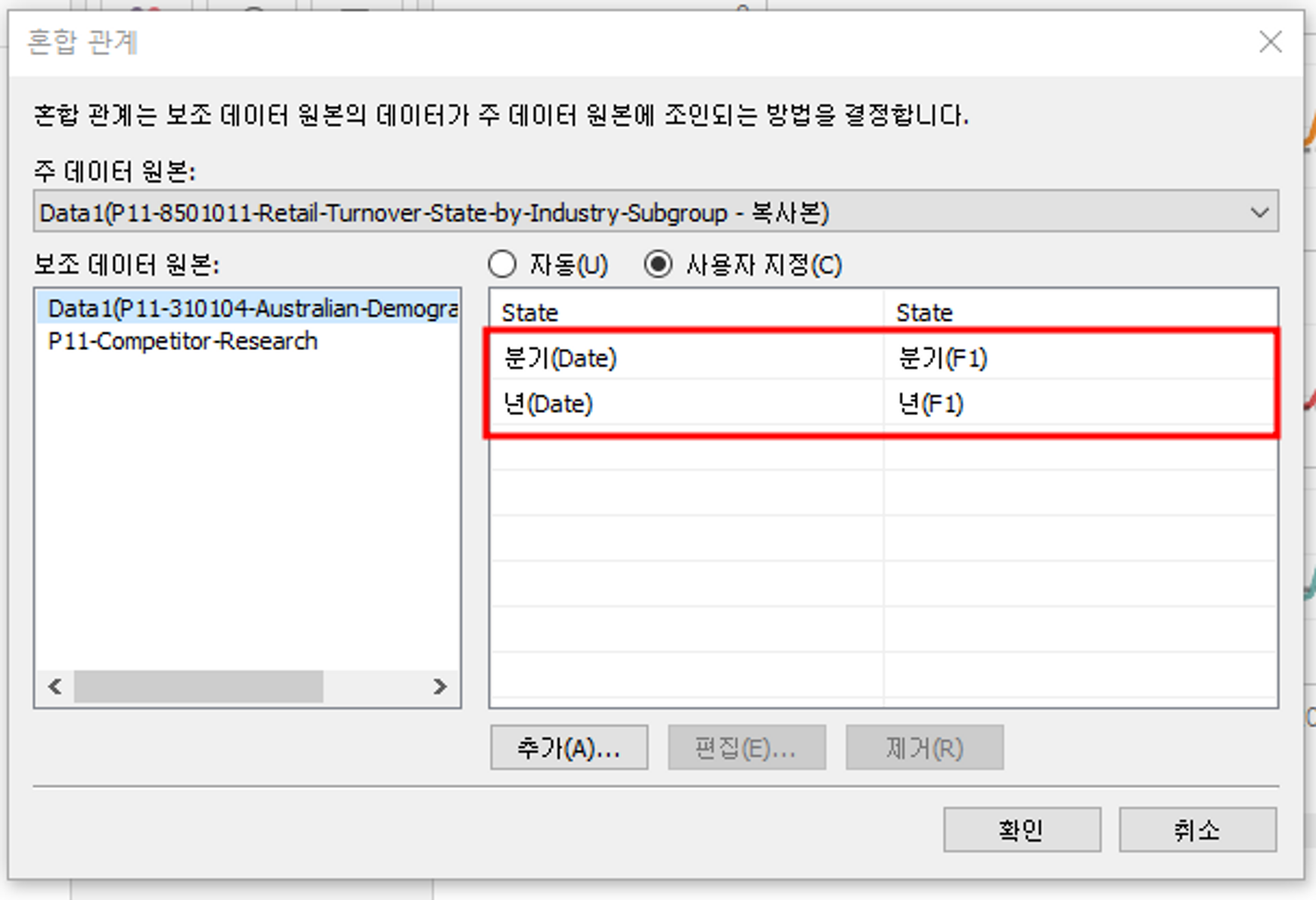
🔎 년과 분기로 관계를 설정한 이유? (월로 설정하지 않음)
올바른 분기의 데이터만 기본 데이터 셋의 분기에 지정되도록 하기 위함이다.
보조 데이터 집합의 데이터를 기본 데이터 집합으로 3중 복제할 수 있는 분기 단위 수준으로만 보고 있다. (혼합은 Left Join이다)
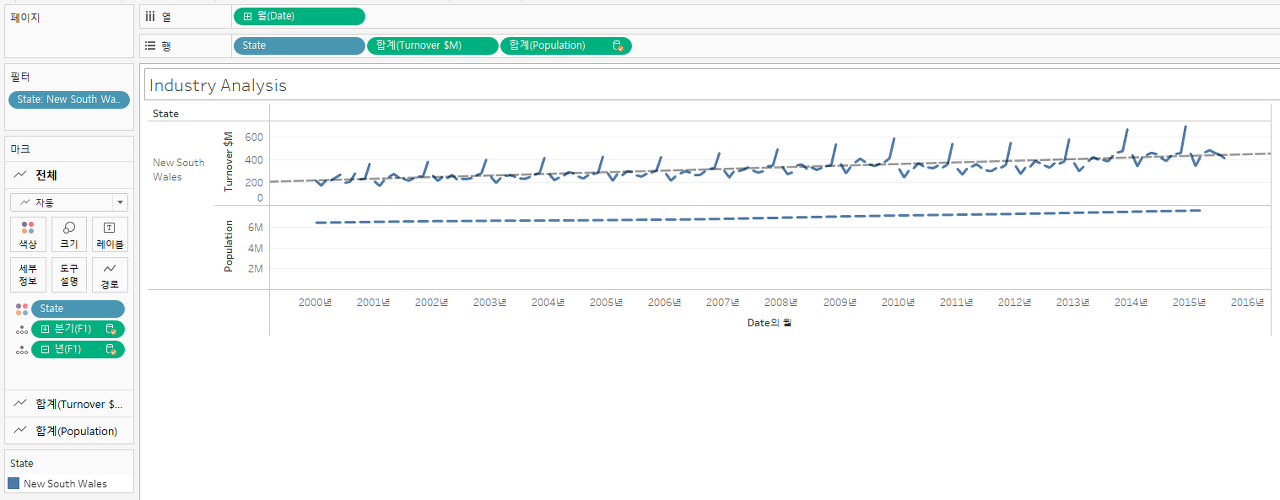
② 분기 관계를 제거한다.

데이터가 달라졌으며, 뭔가 잘못되었다는 것을 알게 되었다 (빨간 박스)
이것은 1년 안에 4개의 값을 갖는 다중 복제가 있다는 것이다. 그래서 우리는 4개의 분기를 가지고 있고 그것들은 실제로 하나의 필드에 결합되고 있다.
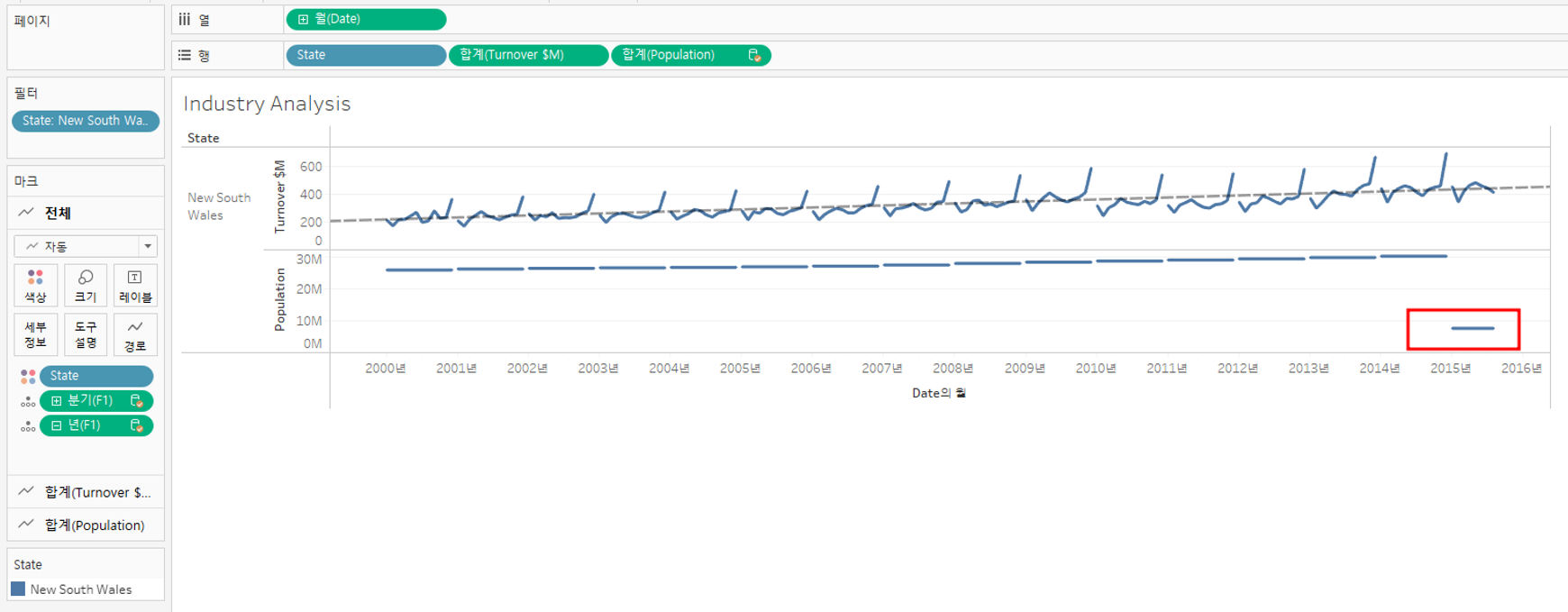
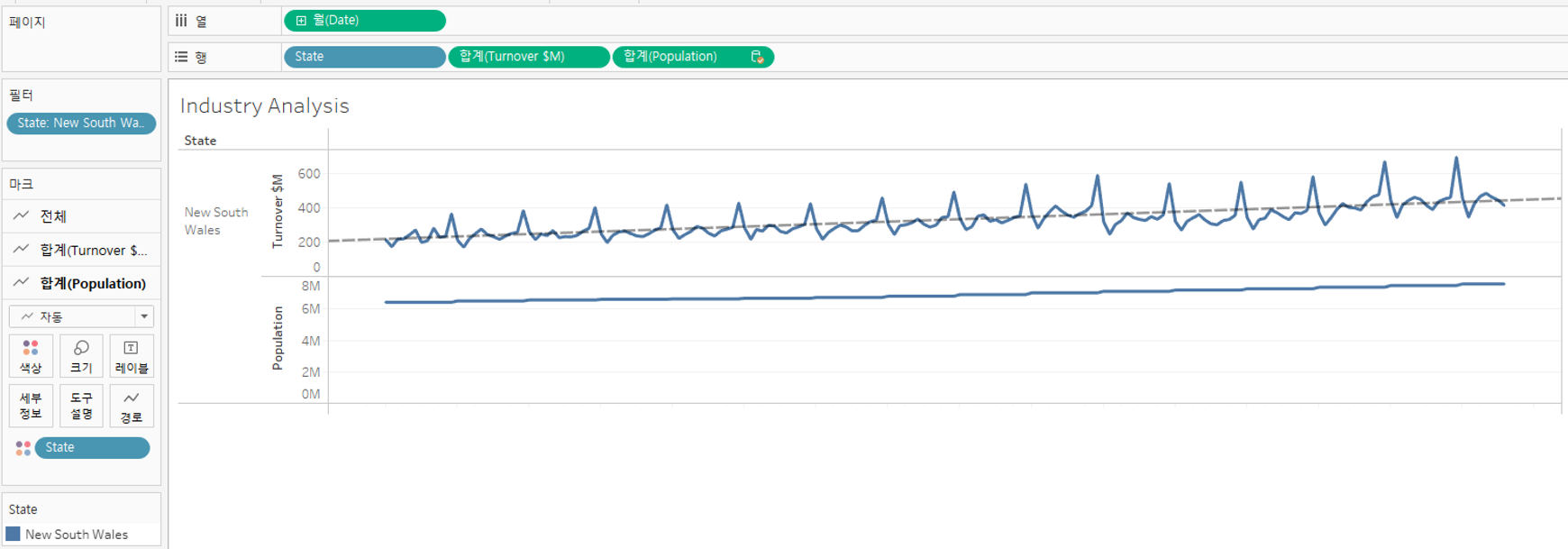
③ 데이터 소스 필터로 매년 3월만 필터링
데이터가 수정됨을 확인할 수 있다.
3) 1인당 매출 구하기
Turnover $M 우클릭 > 만들기 > 계산된 필드
SUM([Turnover $M]) / SUM([Data1(P11-310104-Australian-Demographic-Statistics)].[Population]) * 1000000

📌 퀸즈랜드, 서호주
- p값이 0.05보다 크기 때문에 통계적으로 유의하지 않다.
→ 시간이 지남에 따라 각 개인이 더 많은 돈을 지출하는 것보다 일부에서 더 많은 돈을 지출하고 있다.
- 매달 1인당 50달러 미만을 지출함
📌 뉴사우스웨일즈, 빅토리아
- 산업 자체가 성장하고 있음
→ 인구 규모에 관계없이 산업 자체가 성장하고 있다.
- 전체 사람들이 더 많이 지출하고 있음
▶ 결론
- 산업은 실제로 빅토리아에서 성장하고 있다. 비즈니스 환경은 뉴사우스웨일즈와 가장 유사하다.
- 1인당 지출 금액이 뉴사우스 웨일즈와 마찬가지로 50달러 이상이다.
- 이 2가지 관점에서 빅토리아는 확장을 고려하기 가장 좋은 주이다.
4) 예측하기
분석 > 모델 - 예측 드래그
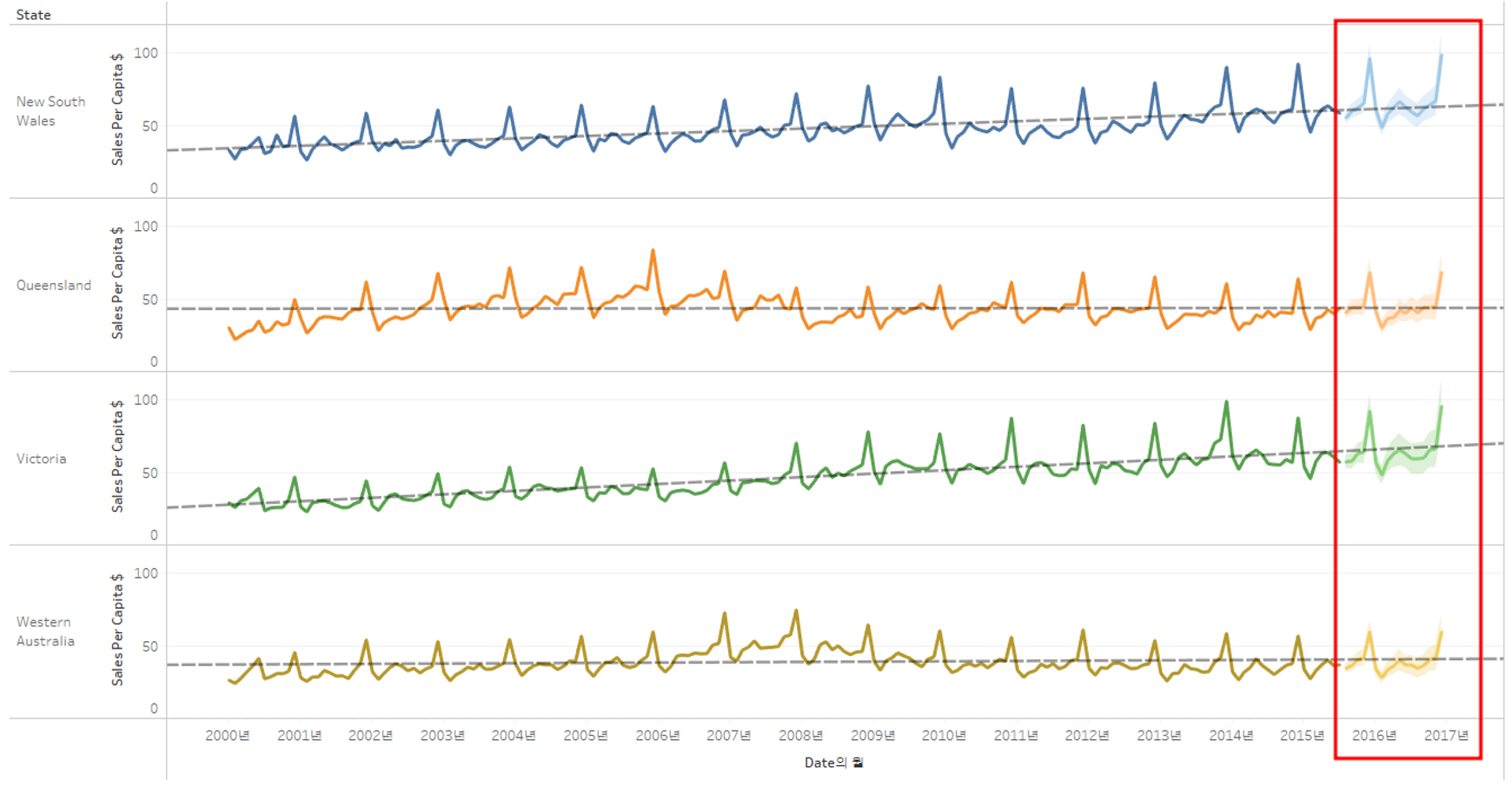
예측에 대한 옵션을 변경할 수 있다.
→ 우클릭 > 예측 > 예측 옵션


4.8 스토리보드

1. 모든 주 중에서 최고의 비즈니스 환경 : 빅토리아
→ 박스 내 세밀하고 상단에 가까워 전체적으로 올릴 수 있는 순 이익에 대한 확실성이 높음을 뜻한다.
2. 모든 주는 의류 소매업에 대해 상승하는 트렌드를 가지고 있다.
하지만 각 주마다 수익이 다른데, 그 이유는 모든 주의 인구가 다르기 때문이다.
그래서 인구를 고려해서 1인당 매출을 계산해서 확인해야한다.
3. 빅토리아의 비즈니스 환경은 이미 진행하고 있는 뉴사우스웨일즈 주의 비즈니스 환경과 유사하다.
그리고 산업 자체가 뉴사우스웨일즈와 마찬가지로 빅토리아에서도 실제로 성장하고 있다.
4. 추가로 여러 주에 대한 몇 가지 예측을 해보았다.
향후 3년 동안의 빅토리아 주의 수익을 미리 추정할 수 있다.
💡 회고
✔ 마무리하며..
확실히 태블로 고급 강의가 어렵다. 심화 내용이 많다보니까 더욱 허덕였던 것 같다.
저녁 9시 넘어서까지 했지만 강의르 다 끝내지 못했다..ㅠㅠ 나머지반이라뉘,,~~
헷갈리거나 이해가 되지 않는 부분도 있었지만, 다음주에 오프라인 강의가 진행되므로 너무 여기에 매달리지 않기로 했다!
내일은 태블로 빠르게 끝내고 파이썬 강의 듣자 :)!💪💪
✔ 유익한 점 & 배운점
실제 보고서와 같이 스토리라인을 작성할 수 있어서 좋았다.
강의를 들을 때는 다소 어렵고 어떤 결과물이 나올지 상상이 잘 되지 않았는데, 스토리라인까지 작성하고 나니 뿌듯하였다.
또한 보고 받는 입장을 생각하며 스토리라인을 작성하는 방법을 알려주셔서 유익했다.
✔ 뿌듯한 점
한 친구가 어떤 부분이 안되어서 바로 다음 섹션 강의로 뛰어넘었다고 했다.
나는 문제 없이 잘 진행했던 부분이라서 같이 어떤 것이 문제인지 찾아보았다. 그러다 한 부분이 빠진 것을 확인하고 이로써 문제가 잘 해결되어서 아주 뿌듯했다! :)😎😎
▼ 내 Tableau Public ▼
송아람 - Profile | Tableau Public
송아람's Tableau Public profile. View interactive data visualizations published by this author.
public.tableau.com