
사실 DACON 코드 리뷰보다 이번 Kaggle 코드 리뷰를 먼저 했다. 그래서인지 아주 부족한 부분이 많긴 하다...!
Kaggle에서 열린 대회 중 하나를 선택하여 코드를 리뷰하는 스터디를 시작했다.
Kaggle을 알게 된 지 얼마 되지 않은 코딩 병아리🐣라
원하는 주제를 찾고, 그에 맞는 대회를 찾는 것부터 버벅거리기 시작했다.
그러다 스터디원분께 조언을 구했고,
캐글 분석에서 가장 많이 하고 입문용으로 좋은 '타이타닉 생존자 예측' 대회의 코드를 리뷰하기로 결정했다.
⭐ 스스로 공부하면서 쓴 포스팅이라 참고하기엔 큰 도움이 되지 않을 듯 합니다 ⭐
1. 대회 내용
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
타이타닉호에 탑승한 승객들의 정보를 바탕으로 생존자를 예측하는 문제에 대한 대회이다.
캐글 리뷰가 처음이라 우선은 한국분의 것을 보고 리뷰을 하고자 한다.
첫번째 코드는 담임쌤이 알려주신 한국인이 작성한 코드이다. (감사합니다 쌤!👼 친절왕)
두번째 코드는 유튜브에서 코드 리뷰하신 것의 코드이다.
첫번째 코드와 두번째 코드에서 진행한 방식이 달라 마지막에 간단하게 비교도 해보았다.
+) 당장 내일이 스터디라,,, 직접 코드를 작성해보지는 않았고 읽기만 했다.
2. 코드 리뷰_첫번째 코드
[Subinium Tutorial] Titanic (Beginner)
Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
www.kaggle.com
1. 라이브러리 불러오기

데이터 분석, 시각화, 머신러닝에 필요한 라이브러리들을 모두 한번에 import했다.
2. 데이터 불러오기
1) pandas 라이브러리로 csv 파일 읽기

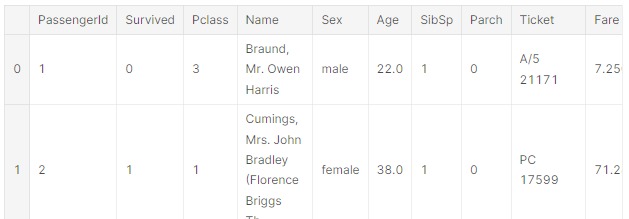
▶ 데이터를 보면 'Name'과 'Ticket'은 불규칙성이 많아 처리가 어렵다.
2) train data와 test data의 정보 확인하기



좌) train data / 우) test data
▶ train data : 데이터 개수 891개 / 특성 12개
▶ test data : 데이터 개수 418개 / 특성 11개
❓ 특성의 개수가 다른 이유는?
→ train data는 '생존여부'를 알고 있기 때문이다.
❗ 주의깊게 봐야 하는 부분 ❗
① 각 컬럼에 NaN 값이 있는지, 있다면 어떻게 처리할 것인가
② 데이터는 float64로 변환할 수 있는지,
3) 필요없는 정보 제거하기

PassengerID, Name, Ticket 컬럼 제거
→ Name, Ticket 컬럼에서 가져올 수 있는 데이터가 없기 때문
→ 해당 문제의 결과물에 'PassengerID'는 필요하기에 훈련데이터에서만 삭제
3. 데이터 처리하기
1) Pclass

1등석, 2등석, 3등석을 나타내는 정보이다. 연속적인 정보가 아니므로 '범주형(카테고리) 데이터'로 인식하고 인코딩해야 함
▶ one-hot-encoding을 pd.get_dummies() 메서드로 인코딩
2) Sex
▶ one-hot-encoding을 pd.get_dummies() 메서드로 인코딩
3) Age

▶ 연속형 데이터로 큰 처리가 필요없음
▶ NaN 데이터가 있으므로 해당 데이터들을 '평균값'으로 채움 (train 데이터셋의 평균 값으로 train, test 데이터셋을 채움)
4) SibSp & Panch
▶ 처리 x
5) Fare
▶ test 데이터셋에 1개의 데이터가 비어있으므로 0으로 채움 (데이터 누락이 아니라 무단 탑승으로 생각)
6) Cabin

▶ NaN 데이터가 대부분이므로 버리기
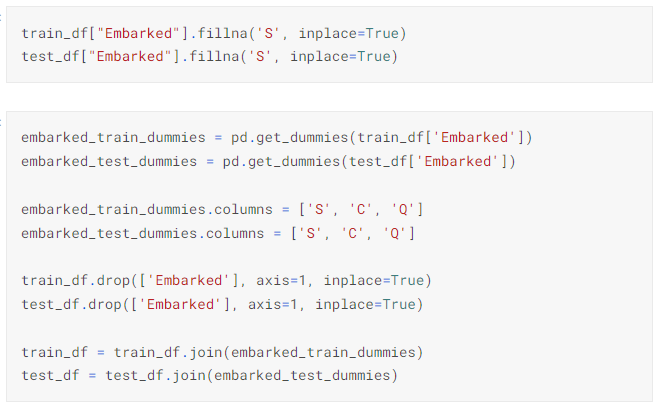
7) Embarked
▶ 데이터를 확인한 결과, S가 대부분이고 NaN 데이터가 있으므로 해당 데이터를 S로 채우기
▶ 문자열로 되어있으니 one-hot-encoding을 pd.get_dummies() 메서드로 인코딩
4. 데이터 나누기

X_train에서는 '생존 여부'의 데이터를 제거
Y_trian에서는 '생존여부'의 데이터만을 가져옴
X_test에서는 PassengerId를 제거
5. 머신러닝 알고리즘 적용하기
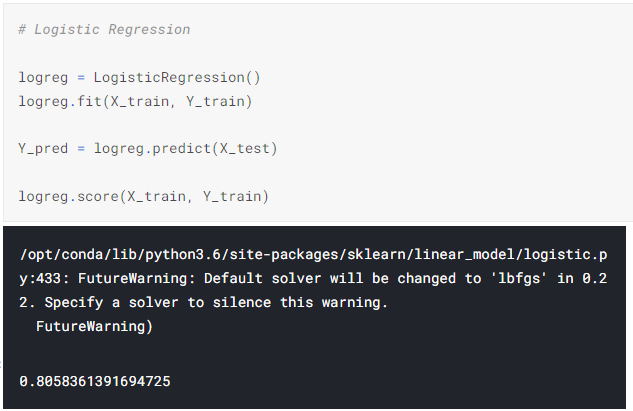
1) Logistic Regression (로지스틱 회귀)
2) SVM

3) Random Forests (랜덤 포레스트)

4) K-NN (K-최근접 이웃)

▶▶ 총 4가지의 알고리즘 모델을 사용하였으며, 모델 중 '랜덤 포레스트 모델'이 0.98로 가장 높았다.
6. 제출용 파일 만들기
가장 좋은 결과를 내었던 '랜덤 포레스트'의 결과로 submission 파일을 만들어 제출

3. 코드 리뷰_두번째 코드
GitHub - minsuk-heo/kaggle-titanic: kaggle titanic solution
kaggle titanic solution. Contribute to minsuk-heo/kaggle-titanic development by creating an account on GitHub.
github.com
4. 첫번째 & 두번째 비교
[3. 데이터 처리]
|
|
1번 코드
|
2번 코드
|
|
Name
|
x
|
이름에서 Mr, Miss, Mrs, others로 나눈 후 매핑 + 'Title'이라는 컬럼 추가 생성
|
|
Pclass
|
one-hot-encoding으로 인코딩
|
x
|
|
Sex
|
one-hot-encoding으로 인코딩
|
map 함수를 사용
|
|
Age
|
NaN 데이터 처리
→ train 데이터의 평균 사용
|
NaN 데이터 처리
→ Title의 각 나이대의 중앙값으로 채움
범위를 나누어 변수 지정
|
|
SibSp & Panch
|
처리하지 않음
|
두 값을 합쳐 'FamilySize'라는 컬럼 추가 생성
각 가족 수대로 map 함수 사용
|
|
Fare
|
test 데이터 셋 중 1개 (0으로 입력)
|
NaN 데이터 처리
→ 각 Pclass 별 중앙값으로 채움
|
|
Cabin
|
NaN 데이터 처리
→ 데이터 사용 x
|
NaN 데이터 처리
→ 각 Pclass 별 중앙값으로 채움
|
|
Embarked
|
NaN 데이터 처리
→ 데이터 중 가장 많은 S로 채움
one-hot-encoding으로 인코딩
|
NaN 데이터 처리
→ 데이터 중 가장 많은 S로 채움
map 함수를 사용
|
[5. 머신러닝 알고리즘 적용]
|
1번 코드
|
2번 코드
|
||
|
로지스틱 회귀
|
81
|
Decision Tree
|
79.69
|
|
SVM
|
88
|
SVM
|
83.5
|
|
랜덤 포레스트
|
98
|
랜덤 포레스트
|
80.59
|
|
KNN
|
83
|
KNN
|
82.6
|
|
Naive Bayes
|
78.78
|
||
급하게 하느라 코드를 상세하게 보지 못하고, 사용한 함수들을 정확히 공부하지 못했다.
이 부분은 스터디 이후 다시 정리해보기로~!🔥
'Data Analysis > Kaggle 코드리뷰' 카테고리의 다른 글
| [Kaggle] House Prices - Advanced Regression Techniques (0) | 2022.06.30 |
|---|---|
| [Kaggle] H&M Personalized Fashion Recommendations (0) | 2022.04.13 |
| [DACON] 구내식당 식수 인원 예측 AI 경진대회 (0) | 2022.02.02 |