
1. 데이터 분석
1.1 문제 정의
1.2 지표 설정 및 분석 계획
✅ 분석 업무는 질문에서 시작한다.
→ 질문에 답하기 위한 분석 지표 설정
- 지난 달에 비해 신규 고객이 얼마나 많이 유입되었는가?
- 월 별 판매 추이가 어떠한가?
- 이탈 고객과 충성 고객의 패턴차이가 있는가?
✅ 질문에 답하기 위한 데이터는 어디에서 나오고 어디에 저장되는가?
- 데이터 웨어하우스 (data warehouse)
- 사용자의 의사결정에 도움을 주기 위하여 기간 시스템의 데이터베이스에 축적된 데이터를 공통의 형식으로 변환해서 관리하는 데이터베이스를 말한다.
1.3 데이터의 종류에 따른 특성
1) 업무 데이터
- 갱신형, 정합성↑, 정확도↑, 정규화
- 기업의 비즈니스 결과로 생성된 데이터
- 마스터 데이터(정보 데이터) : 고객정보, 상품정보, 카테고리정보 등
- 트랜잭션 데이터 (행동 데이터) : 구매, 배송, 리뷰 작성 등
- 분석을 하기 위해서 join을 많이 진행함
2) 로그 데이터
- 누적형
- 사용자의 접속 기간, 클릭 이벤트, ip, 기기, 세션 등의 정보를 저장한 데이터
- 사용자 행동 분석을 통해 웹/앱의 ui/ux 개선하고자 할 때 주로 사용
- 정확도는 업무 데이터에 비해 낮음 (크롤러의 로그 포함 고려 필요)
1.4 데이터 분석 과정
- DB
- ETL (Extract, Transform, Load)
- Data Warehouse : 여러 시스템의 데이터를 하나의 저장소에 통합)
- 분석 (SQL 쿼리 결과를 BI도구, 파이썬, R, 스프레드시트 등의 도구로 분석 진행)
1.5 데이터 분석 세부 과정
1) 탐색
- 데이터와 관련된 주제는 무엇인가?
- 데이터는 어디서 생성되었는가?
- 저장된 테이블은 무엇인가?
2) 프로파일링
데이터 정합성, 품질, 분포 등을 파악 (고유값, 개수, 값의 분포/범위, 이상치, 중복값, 결측값 등)
3) 정제
잘못된 데이터, 불완전한 데이터, 결측값 처리, 형 변환
4) 셰이핑
분석할 결과 테이블을 만드는 과정 (테이블 조인, 컬럼 선택, 집계 등)
5) 분석
통계, 시각화 등
2. 데이터 파악
📌 northwind 데이터 셋 : 전 세계에 식품을 수출하는 가상의 식품회사의 샘플 데이터
2.1 ERD 보기
데이터 우클릭 > 다이어그램 보기

2.2 테이블 관계
dbeaver는 다른 ERD와는 다른 관계 표기법을 사용한다.


- products가 없는 categories가 있을 수 있음 (0..1 관계이기 때문)
- categories가 없는 products가 있을 수 있음 (0..N 관계이기 때문)
- products의 FK인 categories가 일반 속성으로 들어갔기 때문에 비식별 관계이다. (점선)
- 하나의 카테고리에는 여러 제품이 존재한다.

- orders가 없는 order_details가 있을 수 없음 (0..N 관계이기 때문)
- order_details가 없는 orders는 있을 수 없음 (1 관계이기 때문)
- order_details의 FK가 식별자이므로 식별 관계이다 (실선)
- 하나의 주문에는 여러 주문 내역이 존재한다.

- 자기 참조 관계
- 해당 테이블에 있는 컬럼을 참조함
2.3 속성 (attribute, column)
| 기본 속성 | 업무로부터 추출한 속성 |
| 설계 속성 | 모델링을 위해 생성된 속성 (ex. 코드, 일련번호) |
| 파생 속성 | 다른 속성으로부터 계산되거나 변형된 속성 (ex. 총 주문금액, 할인 적용된 금액) |
2.4 식별자
각각의 개체를 구분할 수 있는 결정자
| 대표성 여부 | 주식별자 | - Primary Key로 지정 (예) 사용자id - 유일성, 최소성, 불변성, 존재성(null x) |
| 보조식별자 | - Unique로 지정 (예) 주민번호, 이메일주소 | |
| 속성의 수 | 단일식별자 | - 하나의 속성으로만 이루어진 식별자 |
| 복합식별자 | - 두개 이상 속성으로 이루어진 식별자 | |
| 스스로 생성 여부 | 내부식별자 | - 엔티티 내부에서 스스로 만들어지는 식별자 |
| 외부식별자 | - 타 에티티와의 관계를 통해 타 엔티티로부터 받아오는 식별자 | |
| 대체 여부 | 본질식별자 | - 업무에 의해 만들어지는 식별자 |
| 인조식별자 | - 인위적으로 만든 식별자 |
2.5 정규화
1) 제 1 정규화
✔ 데이터의 중복 제거

2) 제 2 정규화
✔ 주식별자 항목 중 코드화 할 수 있는 속성 분리
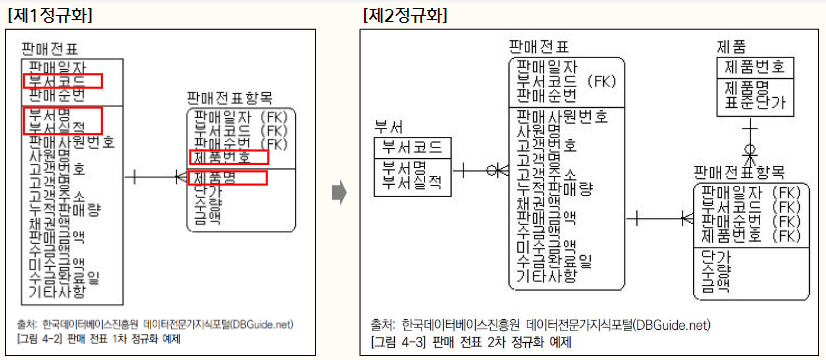
✔ 일반 속성 항목 중 코드화 할 수 있는 속성 분리

2.6 기본 데이터 타입
1) 숫자형
| 정수 | smallint | 2bytes | -32769~32767 |
| integer | 4bytes | -2147483648~2147483647 | |
| bigint | 8bytes | -9223372036854775808~9223372036854775807 | |
| 실수 - 고정 소수점 | numeric | 가변적 | 소수점앞최대131072 자리, 소수점이하최대16383 자리 ※ numeric(precision, scale) 형태로선언 |
| decimal | |||
| 실수 - 부동 소수점 | real | 4bytes | 소수점뒤6자리숫자 |
| double precision | 8bytes | 소수점뒤15자리숫자 | |
| 자동 증가 정수 | smallserial | 2bytes | 1~32767 |
| seiral | 4bytes | 1 ~ 2147483647 | |
| bigserial | 8bytes | 1 ~ 9223372036854775807 |
2) 문자형
| 데이터 타입 | 설명 |
| carh (n) character (n) |
길이가 n인 고정 길이 데이터 타입 |
| varchar (n) character varying (n) |
최대 길이가 n인 가변 길이 데이터 타입 |
| text | 길이 제한이 없는 가변 길이 데이터 타입 (비표준) |
3) 날짜, 시간형
| 데이터 타입 | 크기 | 설명 | 기본 형태 |
| timestamp | 8byte | 날짜와 시간 | YYYY-MM-DD HH:MI:SS.MS [TIMEZONE] |
| date | 4byte | 날짜 (시간 미포함) | YYYY-MM-DD |
| time | 8byte | 시간 (날짜 미포함) | HH:MI:SS.MS [TIMEZONE] |
| interval | 16byte | 날짜 차이 | 1 days, 1 mon, 100 years |
2.7 테이블 목록
1) 테이블 목록 조회
select * from pg_tables
where schemaname = 'northwind'
order by 2;
✔ 테이블 간의 관계, 데이터를 조회해보면서 테이블의 용도를 추측하여 목록 작성하기
| 테이블명 | 테이블 설명 | 데이터 갯수 | 특이사항 |
| categories | 식품 카테고리(이름, 설명, 사진) | 8 | |
| customer_customer_demo | 0 | 정보 없음 | |
| customer_demographics | 0 | 정보 없음 | |
| customers | 고객 인적사항 | 91 | |
| employee_territories | 직원 영역별 id | 49 | |
| employees | 직원 인적사항 | 9 | |
| order_details | 주문에 대한 제품 가격, 양, 할인율 | 2155 | |
| orders | 주문 날짜와 배송 정보 | 830 | |
| products | 제품 정보 | 77 | |
| region | 지역 | 4 | |
| shippers | 배송 회사 | 6 | |
| suppliers | 공급자의 회사와 인적사항 | 29 | |
| territories | 각 주의 영역 id와 지역id | 53 | |
| us_states | 각 주의 약자와 지역 | 51 |
2) 테이블 상세 정보
→ information_schema.columns
-- 컬럼별 상세정보
select table_name as 테이블명
, column_name as 컬럼명
, column_default as 디폴트값
, is_nullable as null가능여부
, data_type as 자료형
, character_maximum_length as 문자열최대자리수
from information_schema.columns
where table_schema ='northwind'
order by table_name, ordinal_position;
3) 제약조건 정보
→ information_schema.constraint_column_usage
-- 제약조건 정보
select table_name, column_name, constraint_name
from information_schema.constraint_column_usage
where table_schema = 'northwind'
order by 1, 3 desc;
4) 테이블 정의서
각 테이블의 컬럼 별로 데이터를 확인하여 데이터에 대한 특징을 정리
→ 각 컬럼 별 설명, 자료형, 자리수, 디폴트값, null 가능 여부, null 갯수, PK 여부, 특이사항

✔ null 갯수 확인 쿼리
각 컬럼의 전체 데이터 (COUNT(*))에서 COUNT(컬럼명)을 빼주어 null 갯수를 구함
→ COUNT(*)는 null 값을 포함한 데이터의 갯수를 출력하고, COUNT(컬럼명)은 null 값을 제외한 데이터의 갯수를 출력하기 때문에 2개를 빼주면 null의 갯수를 구할 수 있다.
select COUNT(*) - COUNT( first_name ) AS first_name
, COUNT(*) - COUNT( title ) AS title
, COUNT(*) - COUNT( title_of_courtesy ) AS title_of_courtesy
, COUNT(*) - COUNT( birth_date ) AS birth_date
, COUNT(*) - COUNT( hire_date ) AS hire_date
, COUNT(*) - COUNT( address ) AS address
, COUNT(*) - COUNT( city ) AS city
, COUNT(*) - COUNT( region ) AS region
, COUNT(*) - COUNT( postal_code ) AS postal_code
, COUNT(*) - COUNT( country ) AS country
, COUNT(*) - COUNT( home_phone ) AS home_phone
, COUNT(*) - COUNT( extension ) AS extension
, COUNT(*) - COUNT( photo ) AS photo
, COUNT(*) - COUNT( notes ) AS notes
, COUNT(*) - COUNT( reports_to ) AS reports_to
, COUNT(*) - COUNT( photo_path ) AS photo_path
from employees;3. 테이블 상세 파악 (팀 프로젝트)
위의 테이블 정의서를 팀 별로 작성한 후 테이블을 상세하게 파악하는 팀 프로젝트가 주어졌다.
우리 조는 각자 테이블을 나누어서 테이블 정의서를 작성하고, 하나의 테이블을 선택하여 그에 맞춰 쿼리를 짜서 파악해보았다.
📌 products 테이블
✔ 상품의 수가 가장 많은 카테고리는?
✔ 재고의 수가 가장 많은 카테고리는?
✔ 평균 단가가 가장 비싼 카테고리는?
✔ 단가가 가장 비싼 제품을 가진 공급사는?
3.1 카테고리 별 상품 수
✔ 가장 상품 수가 많은 카테고리는 Confections이다.
SELECT c.category_id, c.category_name, count(c.category_id)
FROM categories c , products p
WHERE c.category_id = p.category_id
GROUP BY c.category_id
ORDER BY count DESC;

3.2 카테고리 별 재고 개수
✔ 재고의 수가 가장 많은 카테고리는 Seafood이다.
SELECT c.category_id, c.category_name, sum(p.units_in_stock)
FROM products p
INNER JOIN categories c
on p.category_id = c.category_id
GROUP BY c.category_id
ORDER BY sum(p.units_in_stock) desc;

3.3 카테고리 별 평균 가격
✔ 평균 단가가 가장 비싼 카테고리는 Meat/Pourtry이다.
SELECT c.category_id, c.category_name, round(avg(unit_price)::numeric,2) as avg
FROM products p, categories c
WHERE c.category_id = p.category_id
GROUP BY c.category_id
ORDER BY avg desc;

3.4 단가가 가장 비싼 제품을 가지고 있는 공급사
✔ 단가가 가장 비싼 제품을 보유한 공급사는 Aux joyeux ecclésiastiques이다.
SELECT s.company_name ,p.product_name , p.unit_price
FROM products p , suppliers s
WHERE s.supplier_id = p.supplier_id
ORDER BY p.unit_price desc
LIMIT 1;
✅ 과제 (자료)




💡 회고
첫 SQL 오프라인 수업을 진행했다.
처음 postgreSQL을 사용해보았는데, MySQL과 비슷하여서 별 다른 불편함은 없었다.
오랜만에 SQL 기본 이론에 대해 복기하는 시간이라서 좋았다.
그리고 이전에는 SQL로 쿼리를 짜서 데이터를 추출하는 것을 위주로 배웠다면, 오늘은 데이터를 테이블, 컬럼 별로 하나씩 뜯어보는 것부터 시작을 하였다.
사실 데이터를 전처리하기 전에 데이터를 파악하는 것이 가장 중요하지만 간과하기 쉬운 부분이기에 이를 해보는 시간을 가질 수 있어서 좋았다.
그리고 하나의 테이블을 다양하게 파악을 해보는 과제가 있어서 기본부터 다시 차근히 할 수 있어서 유익했다! :)
'웅진X유데미 STARTERS > TIL (Today I Learned)' 카테고리의 다른 글
| [스타터스 TIL] 47일차.SQL 실전 트레이닝 (3) - CTE, 윈도우 함수 (0) | 2023.04.13 |
|---|---|
| [스타터스 TIL] 46일차.SQL 실전 트레이닝 (2) - 컬럼 연산자, 날짜/시간형 데이터, 다중 행 함수 (0) | 2023.04.11 |
| [스타터스 TIL] 44일차.태블로 실전 트레이닝 (20) - 태블로 자격증 공부 (Test 1, Test 2) (1) | 2023.04.08 |
| [스타터스 TIL] 43일차.태블로 실전 트레이닝 (19) - 태블로 자격증 공부 (Test 4, Test 5) (0) | 2023.04.07 |
| [스타터스 TIL] 42일차.태블로 실전 트레이닝 (18) - 태블로 자격증 공부 (Test 3) (0) | 2023.04.05 |